
TL;DR:
- ML-BENCH assesses LLMs’ effectiveness in utilizing existing functions in open-source libraries for real-world programming.
- It challenges the traditional focus on code generation benchmarks by evaluating LLMs’ ability to execute code from established libraries with precise parameter usage.
- A collaboration between Yale University, Nanjing University, and Peking University, ML-BENCH provides a comprehensive benchmark dataset with instructive ground truth code examples.
- Metrics like Pass@k and Parameter Hit Precision are employed to evaluate GPT-3.5-16k, GPT-4-32k, Claude 2, and CodeLlama in ML-BENCH, revealing GPT models and Claude 2 as top performers.
- GPT-4 shows improvement but still completes only 39.73% of tasks, highlighting the need for LLMs to understand lengthy documentation.
- The introduction of the ML-AGENT addresses deficiencies and empowers LLMs to comprehend human language, generate efficient code, and perform complex tasks.
Main AI News:
In the realm of artificial intelligence, Language Model Models (LLMs) have emerged as formidable tools for diverse programming-related tasks. While their prowess in controlled environments is well-documented, the transition to practical programming scenarios presents a formidable hurdle. This paper introduces ML-BENCH, a groundbreaking approach that scrutinizes the effectiveness of LLMs in harnessing the power of existing functions within open-source libraries, aligning with real-world demands.
In conventional code generation benchmarks, LLMs are evaluated on their ability to craft entirely new code from scratch. However, in actual programming practices, the reliance on pre-existing, publicly accessible libraries is commonplace. These libraries, battle-tested and refined, provide reliable solutions to a multitude of challenges. Hence, the evaluation of LLMs should extend beyond mere code generation capabilities and encompass their adeptness at executing code derived from open-source libraries with precise parameter usage.
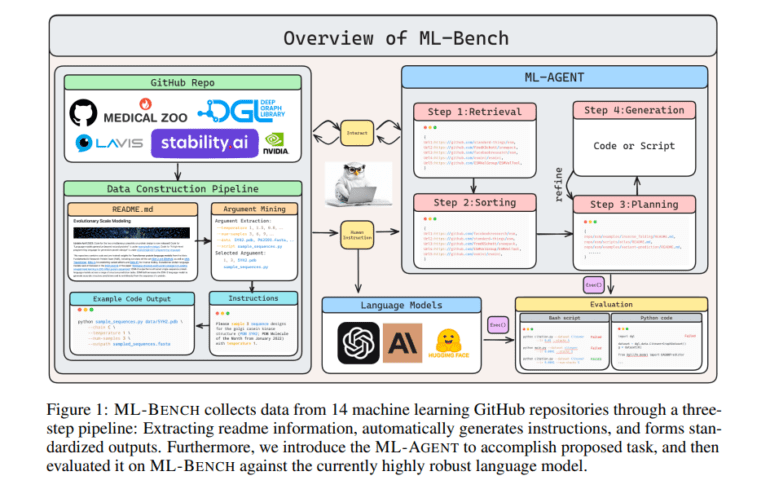
A collaborative effort between Yale University, Nanjing University, and Peking University introduces ML-BENCH, a comprehensive benchmark dataset that delves into the realms of LLM comprehension of user instructions, GitHub repository navigation, and the production of executable code. ML-BENCH offers a trove of high-quality, instructive ground truth code samples that adhere meticulously to the given instructions. With a repository of 9,444 examples spanning 130 tasks and encompassing 14 prominent machine learning GitHub repositories, ML-BENCH sets a new standard in LLM evaluation.
The research employs two critical metrics, Pass@k and Parameter Hit Precision, to assess the capabilities of GPT-3.5-16k, GPT-4-32k, Claude 2, and CodeLlama within the ML-BENCH framework. Notably, the empirical findings indicate that GPT models and Claude 2 outshine CodeLlama by a substantial margin. Despite GPT-4 exhibiting a significant performance boost over other LLMs, it achieves completion in only 39.73% of the tasks conducted. Other renowned LLMs exhibit tendencies towards hallucinations and underperformance, emphasizing the need for comprehensive language comprehension.
A pivotal technological contribution lies in the introduction of the ML-AGENT, an autonomous language agent engineered to address the identified deficiencies through meticulous error analysis. These agents possess the ability to comprehend human language and instructions, generate efficient code, and tackle complex tasks with finesse.
The synergy between ML-Bench and ML-Agent represents a monumental stride in the realm of automated machine learning processes. Researchers and practitioners alike are urged to explore the possibilities unveiled by this pioneering research, promising a transformative impact on the landscape of practical programming with LLMs.
Conclusion:
The advent of ML-BENCH and the development of ML-AGENT mark a significant step forward in the evaluation and application of LLMs in real-world programming scenarios. This innovation has the potential to reshape the market by enabling more reliable and efficient use of LLMs in software development, driving increased productivity and reducing the gap between experimental capabilities and practical demands. Researchers and industry practitioners should take note of these advancements, as they hold the promise of transforming the landscape of AI-driven programming.