
- MoMA introduces a pioneering approach to personalized image generation, sidestepping the need for extensive tweaking or training data.
- Leveraging an open vocabulary and logical textual prompts, MoMA seamlessly integrates visual characteristics with textual cues.
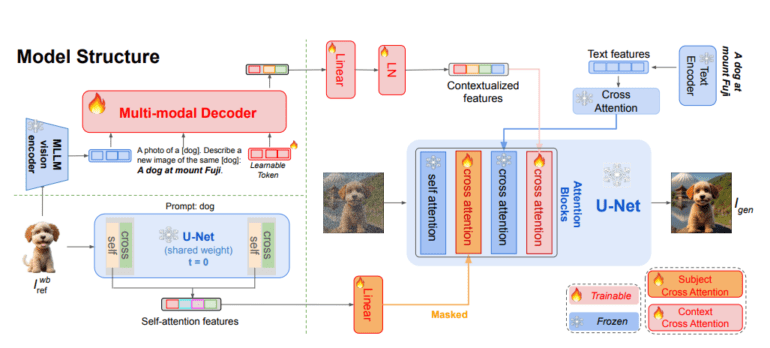
- The model’s architecture comprises a generative multimodal decoder, UNet self-attention layers, and a UNet diffusion model.
- Training data for MoMA consisted of 282K image/caption/image-mask triplets, selectively curated to streamline the process.
- Empirical evaluations demonstrate MoMA’s superiority in detail fidelity and object identity preservation, with minimal computational overhead.
- MoMA’s versatility allows for seamless integration with community models, unlocking new possibilities in image generation and machine learning.
Main AI News:
Cutting-edge image generation has witnessed remarkable advancements, largely propelled by the advent of expansive text-to-image diffusion models such as GLIDE, DALL-E 2, Imagen, Stable Diffusion, and eDiff-I. These models have empowered users to craft lifelike images through diverse textual cues. However, while effective, conventional methods often fall short in conveying intricate visual details, prompting the emergence of image-conditioned generation techniques like Kandinsky and Stable Unclip.
Taking a step further, personalized image generation represents the pinnacle of this evolution. Traditionally, approaches have relied on learnable text tokens to depict target concepts, alongside converting input photos into text. Yet, the resource-intensive nature of instance-specific tuning and model storage has posed significant challenges, limiting the scalability and practicality of such methods.
Enter MoMA, a groundbreaking model developed by ByteDance and Rutgers University, poised to redefine personalized image generation without the need for extensive tweaking or training data. By leveraging an open vocabulary and adeptly integrating logical textual prompts, MoMA excels in preserving detail fidelity and object identities, while facilitating rapid picture customization.
The architecture of MoMA comprises three integral components:
- Generative Multimodal Decoder: Researchers utilize this decoder to extract features from reference images, subsequently adapting them based on target prompts to yield contextualized image features.
- UNet Self-Attention Layers: The original UNet architecture’s self-attention layers are employed to isolate object image features, achieved by replacing the background with white color, thereby focusing solely on object pixels.
- UNet Diffusion Model: Leveraging object-cross-attention layers and contextualized picture attributes, this model generates new images, with dedicated training for optimal performance.
- To train MoMA, the team curated a dataset of 282K image/caption/image-mask triplets from the OpenImage-V7 dataset. Notably, subjects related to humans, color, form, and texture keywords were selectively eliminated to streamline training.
Empirical evaluations underscore the superiority of MoMA. By harnessing Multimodal Large Language Models (MLLMs), MoMA seamlessly integrates visual characteristics with textual prompts, enabling nuanced alterations to both backdrop context and object texture. Notably, the proposed self-attention shortcut bolsters detail quality while imposing minimal computational overhead.
MoMA’s versatility is unparalleled, offering seamless integration with community models fine-tuned using similar architectures. This interoperability unlocks a realm of possibilities in image generation and machine learning, heralding a new era of personalized visual content creation.
Conclusion:
MoMA’s innovative approach to personalized image generation represents a significant advancement in the market. By eliminating the need for extensive tweaking and leveraging an open vocabulary, MoMA streamlines the process, making it more accessible to a broader range of users. Its superior performance in detail fidelity and object identity preservation, coupled with its seamless integration capabilities, positions MoMA as a game-changer in the field of image generation, offering immense potential for diverse applications across various industries.