
TL;DR:
- The scarcity of large-scale music datasets with natural language captions has been a major hurdle in text-to-music production research.
- The Music Understanding LLaMA (MU-LLaMA) model, developed by a collaborative research team, offers a groundbreaking solution by generating music question-answer pairs from existing audio captioning datasets.
- MU-LLaMA employs the MERT model as a music encoder, enabling it to comprehend music and respond to queries, while also automatically generating subtitles for a wide range of music files from public resources.
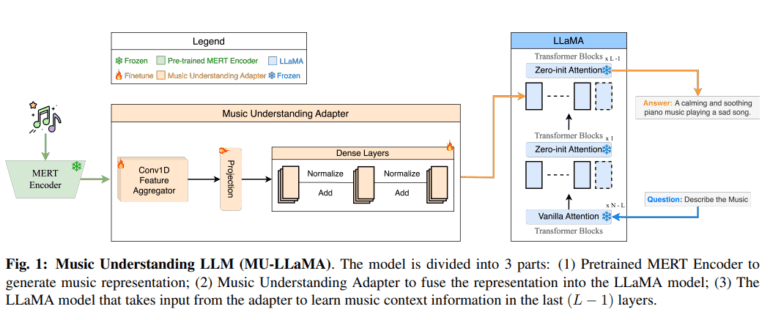
- Its architecture involves a frozen MERT encoder, a neural network with three sub-blocks, and skip connections, allowing it to provide contextually rich responses in music understanding and captioning tasks.
- MU-LLaMA outperforms existing models in music question answering and music captioning, demonstrating its superior performance in BLEU, METEOR, ROUGE-L, and BERT-Score metrics.
Main AI News:
The challenge of acquiring large-scale music datasets accompanied by natural language captions has long hindered the progress of text-to-music production. While closed-source captioned datasets do exist, their scarcity poses a formidable obstacle to advancing research in this field. To overcome this challenge, a groundbreaking solution has emerged in the form of the Music Understanding LLaMA (MU-LLaMA) model, designed to excel in captioning and music question answering. This model leverages a unique approach to generate numerous music question-answer pairs from existing audio captioning datasets.
The current landscape of text-to-music creation techniques is marked by limitations, often exacerbated by the prevalence of closed-source datasets due to licensing restrictions. Building upon Meta’s LLaMA model and harnessing the power of the Music Understanding Encoder-Decoder architecture, a collaborative research effort between ARC Lab, Tencent PCG, and the National University of Singapore has given birth to MU-LLaMA. Notably, the study introduces the MERT model as the music encoder, endowing the model with the capacity to comprehend music and respond to inquiries. This innovative approach, driven by the automatic generation of subtitles for an extensive array of music files from public resources, aims to bridge the existing gaps in the field.
The methodology underpinning MU-LLaMA is founded on meticulously designed architecture, commencing with a frozen MERT encoder that generates embeddings of musical attributes. These embeddings then undergo processing through a robust neural network comprising three sub-blocks and a 1D convolutional layer. Each sub-block incorporates elements such as the linear layer, SiLU activation function, and normalization components interconnected by skip connections. The last (L-1) layers of the LLaMA model utilize the resulting embeddings, furnishing crucial music context information for the question-answering process. While the music understanding adapter is fine-tuned during training, the MERT encoder and LLaMA’s Transformer layers remain immutable. This approach empowers MU-LLaMA to craft captions and address queries in alignment with the music’s context.
MU-LLaMA’s performance is rigorously evaluated using key text generation metrics, including BLEU, METEOR, ROUGE-L, and BERT-Score. The model undergoes testing in two primary subtasks: music question answering and music captioning. Comparative assessments are made against existing large language model (LLM) based models designed for music-related inquiries, specifically the LTU model and the LLaMA Adapter with ImageBind encoder. Across all metrics, MU-LLaMA consistently outperforms its counterparts, showcasing its remarkable ability to provide accurate and contextually relevant responses to music-related queries. In the realm of music captioning, MU-LLaMA faces competition from Whisper Audio Captioning (WAC), MusCaps, LTU, and LP-MusicCaps, where it distinguishes itself by exhibiting superior performance in terms of BLEU, METEOR, and ROUGE-L criteria.
Conclusion:
The introduction of MU-LLaMA signifies a significant advancement in the field of music understanding and generation. Its ability to overcome the challenge of limited music datasets and provide contextually relevant responses positions it as a valuable tool for music-related applications and content generation in the market. This innovation has the potential to revolutionize music production and enhance user experiences across various platforms and industries.