
- Language models face privacy and copyright issues due to training on large datasets.
- Data owners are demanding data removal, driving the need for machine unlearning techniques.
- Exact unlearning methods are not feasible for large models; approximate methods are emerging.
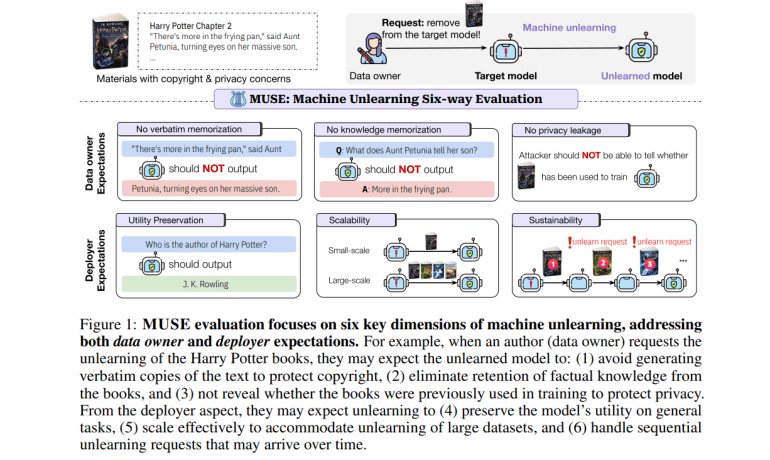
- MUSE (Machine Unlearning Six-Way Evaluation) provides a detailed framework to evaluate unlearning algorithms.
- MUSE assesses six key areas: verbatim memorization, knowledge memorization, privacy leakage, utility preservation, scalability, and sustainability.
- Evaluation of eight algorithms using NEWS and BOOKS datasets revealed challenges, particularly with privacy leakage and scalability.
Main AI News:
Language models (LMs) face growing concerns regarding privacy and copyright due to their training on extensive text datasets. The accidental inclusion of private or copyrighted material has sparked legal and ethical challenges, including copyright disputes and compliance with regulations like GDPR. As data owners demand the removal of their data from these models, the field is shifting focus towards effective machine unlearning methods. Researchers are exploring ways to modify existing models to function as if certain data had never been included, all while maintaining performance and efficiency.
Early efforts to tackle machine unlearning in LMs have included exact unlearning methods, which strive to replicate models retrained without the data in question. These approaches, however, are not feasible for modern large language models due to their computational demands. As a result, approximate unlearning methods have gained traction. These include techniques such as Gradient Ascent for parameter optimization, localization-informed unlearning targeting specific model components, and in-context unlearning that adjusts model outputs with external knowledge. Additionally, researchers are investigating unlearning for specific tasks and removing harmful model behaviors.
Current evaluation methods for machine unlearning focus on tasks like question answering or sentence completion, using metrics such as familiarity scores and comparisons with retrained models. However, these evaluations often fall short of addressing real-world issues like scalability and handling multiple unlearning requests.
In response, researchers from the University of Washington, Princeton University, the University of Southern California, the University of Chicago, and Google Research have introduced MUSE (Machine Unlearning Six-Way Evaluation). This framework offers a thorough evaluation of machine unlearning algorithms for language models, addressing key aspects of data owner and deployer needs. MUSE assesses the algorithms’ effectiveness in eliminating verbatim memorization, knowledge memorization, and privacy leakage, while also evaluating their utility preservation, scalability, and performance sustainability across multiple unlearning requests. The framework evaluates eight machine unlearning algorithms using datasets focused on unlearning Harry Potter books and news articles, providing a comprehensive view of the state and limitations of current techniques.
MUSE introduces six critical evaluation metrics:
- Data Owner Expectations:
- Verbatim Memorization: Assessed by comparing model continuations with true sequences using ROUGE-L F1 score.
- Knowledge Memorization: Evaluated by comparing model answers to true answers derived from the forget set using ROUGE scores.
- Privacy Leakage: Detected via membership inference attacks to determine if the forget set information remains within the model.
- Model Deployer Expectations:
- Utility Preservation: Measured by the model’s performance on retained data using the knowledge memorization metric.
- Scalability: Examined by performance on forget sets of various sizes.
- Sustainability: Analyzed by tracking performance across sequential unlearning requests.
Using the NEWS and BOOKS datasets, MUSE highlights significant challenges in machine unlearning for language models. While many methods successfully address verbatim and knowledge memorization, issues with privacy leakage and scalability persist. The evaluation reveals that current methods often degrade model utility and struggle with sequential unlearning requests, emphasizing the need for more balanced and effective approaches to satisfy both data owners and model deployers.
Conclusion:
The introduction of the MUSE framework highlights the growing complexity of machine unlearning in language models. As privacy and copyright concerns intensify, the need for effective unlearning techniques becomes more critical. MUSE’s comprehensive approach provides valuable insights into the effectiveness and limitations of current methods, revealing significant issues such as privacy leakage and scalability challenges. For the market, this underscores a pressing demand for more refined and balanced unlearning solutions. Companies and researchers must address these challenges to meet both data owner and deployer expectations, ensuring the advancement of machine learning technologies while adhering to evolving regulatory standards.