
- Expansive language models (ELMs) are prevalent in various domains.
- Hallucinations, nonsensical outputs, are a challenge for ELMs.
- DeepMind’s method employs self-assessment to identify unreliable responses.
- The approach utilizes conformal prediction techniques.
- Evaluation on datasets like Temporal Sequences and TriviaQA shows promising results.
- The method allows models to abstain from providing unreliable answers.
Main AI News:
Expansive language models (ELMs), sophisticated artificial neural networks that possess the capability to process, generate, and manipulate texts across multiple human languages, have witnessed a surge in their prevalence recently. These models are now deployed across diverse domains, aiding in swift information retrieval, crafting tailored content, and deciphering intricate textual inputs.
Despite the impressive text generation capabilities exhibited by contemporary ELMs, there exists a susceptibility to what is termed as hallucinations. In this context, hallucinations denote instances where an ELM produces entirely nonsensical, inaccurate, or unsuitable outputs. To address this challenge, researchers at DeepMind have pioneered a novel methodology aimed at discerning situations where an ELM should refrain from responding to a query, opting instead for a response such as “I don’t know,” thereby mitigating the risk of generating nonsensical or erroneous answers. The team’s innovative approach, detailed in a pre-published paper on arXiv, entails employing ELMs to evaluate their own potential responses.
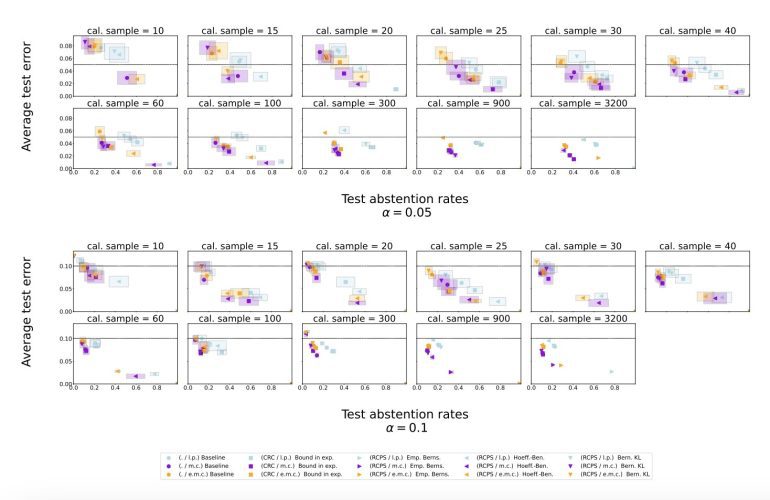
“Expanding upon previous methodologies that prioritize self-consistency as a more dependable indicator of model confidence, we advocate for utilizing the ELM itself to self-assess the similarity between each generated response for a given query,” elucidated Yasin Abbasi Yadkori, Ilja Kuzborskij, and their collaborators in their scholarly contribution. “Furthermore, we harness conformal prediction techniques to devise an abstention mechanism that capitalizes on robust theoretical assurances regarding the hallucination rate (error rate).”
Yadkori, Kuzborskij, and their research cohort subjected their proposed methodology to rigorous evaluation to mitigate ELM hallucinations through a series of experiments conducted on Temporal Sequences and TriviaQA, both publicly accessible datasets housing queries and corresponding responses. Notably, they applied their approach to Gemini Pro, an ELM developed by Google and unveiled in 2023.
“In our experimental assessments, the resultant conformal abstention technique consistently constrains the hallucination rate across various closed-book, open-domain generative question answering datasets, while simultaneously exhibiting a significantly less conservative abstention rate in datasets featuring lengthy responses (Temporal Sequences) in comparison to methodologies relying on log-probability scores to gauge uncertainty. Moreover, our approach achieves commensurate performance on datasets with concise answers (TriviaQA),” articulated the researchers.
“For automated evaluation of experiments, establishing the equivalence between two responses relative to a question is imperative. Adhering to established conventions, we employ a thresholded similarity metric to ascertain response equivalence, supplemented by a method for fine-tuning the threshold through conformal prediction, underpinning the accuracy of equivalence prediction, which holds potential significance in its own right.”
The findings stemming from the research endeavors of this team at DeepMind indicate that the conformal calibration and similarity scoring framework effectively alleviate ELM hallucinations, empowering the model to abstain from responding to queries when the generated answer is likely to be nonsensical or unreliable. Notably, the newly proposed approach surpasses simplistic baseline scoring methodologies.
This recent investigation by DeepMind is poised to inform the formulation of analogous methodologies aimed at enhancing the dependability of ELMs and curbing instances of hallucination. Collectively, these endeavors are poised to propel the evolution of these models, facilitating their widespread adoption across professional spheres globally.
Conclusion:
DeepMind’s innovative method to mitigate hallucinations in expansive language models marks a significant step towards enhancing their reliability. As language models become increasingly integrated into various professional settings, such advancements will be instrumental in ensuring the accuracy and trustworthiness of generated outputs, thus bolstering their acceptance and utilization across diverse market segments.