
TL;DR:
- Concerns arise over legal risks and performance trade-offs of language models (LMs) trained on copyrighted content.
- SILO approach proposes splitting training data into parametric and nonparametric subsets to enhance risk-performance balance.
- Nonparametric component (datastore) is used during inference, allowing retrieval of high-risk data without compromising model training.
- SILO’s unique features offer better alignment with data usage restrictions and improved attribution to data contributors.
- Study introduces SILO, a novel nonparametric LM model, and evaluates it against a parametric baseline (Pythia).
- SILO demonstrates competitive performance within certain domains and bridges performance gaps with advanced nonparametric techniques.
- Expansion of SILO’s datastore and nonparametric model could further improve performance across domains.
Main AI News:
The ongoing discourse around massive language models (LMs) has been significantly influenced by concerns surrounding copyright and legal implications. The intricate interplay between legal exposure and model efficacy remains central to this discourse. Striving to solely employ permissively licensed or publicly accessible data for training purposes invariably compromises the precision of these models. This predicament stems from the fact that conventional LM training datasets span an array of subjects, a challenge exacerbated by the scarcity of permissible data sources, which are primarily tied to expired copyrights, government archives, and liberally licensed code.
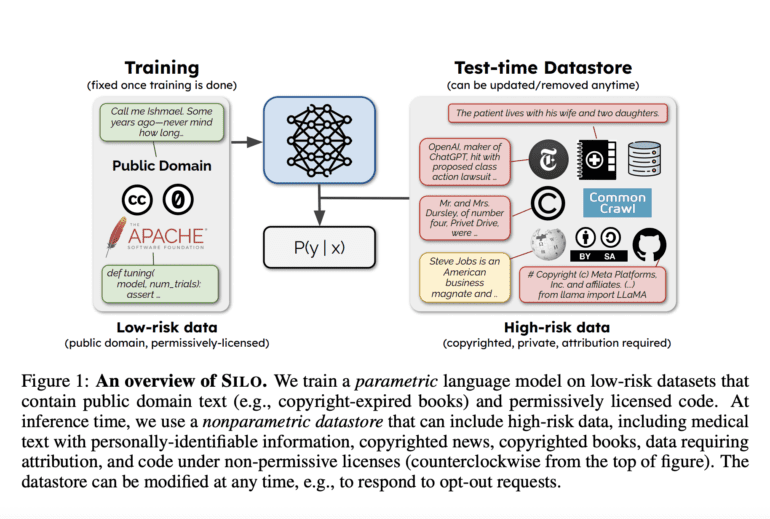
A collaborative study recently conducted by the University of Washington, UC Berkeley, and the Allen Institute for AI has introduced a groundbreaking solution to this conundrum by proposing a dichotomy in training data – separating it into parametric and nonparametric subsets – to optimize the risk-performance balance. This innovative methodology involves training LM parameters on low-risk data, subsequently integrating them into a nonparametric component (a datastore) reserved exclusively for inference purposes. When faced with high-risk data, this nonparametric datastore can be tapped into to augment model predictions beyond the training phase. A noteworthy feature is that developers can selectively remove their data from the datastore, even at the level of individual instances.
Furthermore, the datastore boasts real-time upgradability. This strategic approach also attributes credit to data contributors by associating model predictions with individual sentences. These advancements collectively empower the model to harmonize effectively with a spectrum of data usage restrictions. In stark contrast, parametric models entail the inextricability of high-risk data post-training, coupled with challenges in scaling data attribution.
To operationalize their proposal, the researchers devised SILO – an innovative nonparametric language model. The foundation of SILO is the OPEN LICENSE CORPUS (OLC), a pioneering pretraining dataset for SILO’s parametric segment. Unlike traditional pretraining datasets, OLC exhibits a pronounced bias toward code and government text, underscoring its distinctiveness. This unique composition, however, introduces the formidable challenge of domain generalization, as the model endeavors to extrapolate insights from highly specialized domains. The study employs three LMs, each with 1.3 billion parameters, trained on distinct subsets of OLC. Subsequently, an inference-time datastore is constructed, capable of integrating high-risk data. Employing two contrasting strategies, the retrieval-in-context approach (RIC-LM) and the nearest-neighbors approach (kNN-LM), the model retrieves text blocks to augment the parametric LM contextually.
The study evaluates SILO’s performance against Pythia, a parametric LM with some shared features but primarily tailored for high-risk data application. Initial findings underscore the difficulty of domain generalization, highlighting SILO’s competitive performance within OLC domains but notable shortcomings beyond them. However, this shortfall is effectively addressed by the introduction of the inference-time datastore. Notably, both kNN-LM and RIC-LM exhibit substantial enhancements in out-of-domain performance. Remarkably, kNN-LM demonstrates superior generalization capabilities, narrowing the performance gap with the Pythia baseline by an impressive average of 90% across diverse domains. Insights gleaned from the analysis underscore the domain-shift resistance of kNN-LM’s nonparametric next-token prediction function, which benefits significantly from data store expansion.
Conclusion:
The SILO model presents a significant advancement in managing legal risks and performance challenges in language models. Its innovative approach of segregating training data and leveraging a nonparametric component showcases the potential to reshape the landscape of language modeling, enabling better compliance with legal constraints while maintaining high-performance standards. This has the potential to revolutionize the language model market by addressing crucial concerns and paving the way for more responsible and effective text generation solutions.