
- Traditional tree ensemble models like XGBoost are dominant in tabular data tasks.
- Deep learning models (e.g., TabNet, NODE) show promise but face challenges with data sparsity and interpretability.
- Intel’s study found XGBoost consistently outperformed deep learning models across diverse datasets.
- XGBoost requires less hyperparameter tuning for optimal performance.
- Combining deep learning with XGBoost in ensembles yields the best results.
Main AI News:
In the realm of solving complex data science problems, the selection of the appropriate model holds utmost significance. For tabular data, traditional tree ensemble models like XGBoost have long reigned supreme in tasks involving classification and regression. Their effectiveness stems from their ability to handle diverse feature types and large datasets efficiently. However, recent advancements in deep learning have posed a challenge to this dominance, claiming superior performance in specific instances.
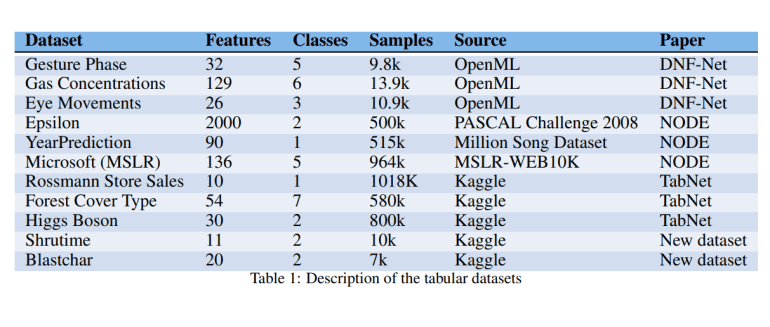
Deep neural networks, renowned for their success in fields like image, audio, and text processing, have increasingly been adapted to handle tabular data. Models such as TabNet, NODE, DNF-Net, and 1D-CNN have emerged as contenders, incorporating innovative approaches like differentiable trees and attention mechanisms. These adaptations aim to address the challenges posed by tabular data, such as data sparsity and mixed feature types, which traditional models like XGBoost manage differently.
Despite the promise shown by deep learning models, rigorous benchmarking against established methods like XGBoost remains essential for validation. Researchers from Intel’s IT AI Group undertook a comprehensive evaluation to compare the performance of XGBoost with that of various deep learning models across diverse tabular datasets. Their findings, surprising to some, consistently showed XGBoost outperforming deep learning models across most datasets, even those specifically chosen to highlight the strengths of deep models. This superiority extended to efficiency in hyperparameter tuning, where XGBoost required fewer adjustments to achieve optimal performance.
However, the study also explored the potential synergies of combining deep learning models with XGBoost in ensemble methods. These hybrid approaches often yielded superior results compared to either standalone XGBoost or individual deep models. Such findings underscore the complementary strengths of different approaches: while XGBoost excels in robust and generalized performance, deep learning models capture intricate patterns that might evade traditional methods.
In conclusion, while deep learning continues to advance and offer promising avenues for tabular data analysis, XGBoost remains a stalwart choice due to its efficiency, reliability, and consistent performance across diverse datasets. The study encourages further exploration into hybrid approaches that leverage the strengths of both deep learning and traditional ensemble methods, promising even greater strides in tackling complex data science challenges.
Conclusion:
The study underscores XGBoost’s enduring superiority in handling tabular data challenges, despite the advancements in deep learning. This finding suggests that while deep learning models offer innovation, XGBoost remains the pragmatic choice for businesses seeking efficient and reliable solutions for their data analytics needs. Understanding the strengths of each approach allows organizations to leverage hybrid strategies effectively, ensuring robust performance across varied datasets and applications in the market.