
TL;DR:
- Harvard’s SAFR AI Lab explores privacy issues in Large Language Models (LLMs).
- Researchers focus on privacy risks, training process integration, data deletion, and copyright concerns.
- Challenges include distinguishing “memorization” from privacy infringement and addressing copyright complexities.
- The survey covers LLM datasets, legal discourse on copyright, and the need for innovative solutions.
- Differential privacy, federated learning, and machine unlearning are discussed as privacy-enhancing techniques.
- The effectiveness of differential privacy and federated learning in mitigating privacy risks is highlighted.
- The survey emphasizes ongoing research and development for the intersection of privacy, copyright, and AI.
Main AI News:
In the realm of AI research, a pressing concern has emerged: the intricate web of privacy issues surrounding Large Language Models (LLMs). A recent survey conducted by the SAFR AI Lab at Harvard Business School delves deep into this complex landscape. This study sheds light on the challenges faced by LLMs, providing valuable insights into potential solutions.
The SAFR AI Lab’s research has a laser focus on privacy risks associated with LLMs. They take a multifaceted approach, covering topics such as integrating privacy into the training process, efficient data deletion from trained models, and addressing copyright concerns. Their commitment to rigorous technical research is evident, with endeavors encompassing algorithm development, theorem proofs, and empirical evaluations.
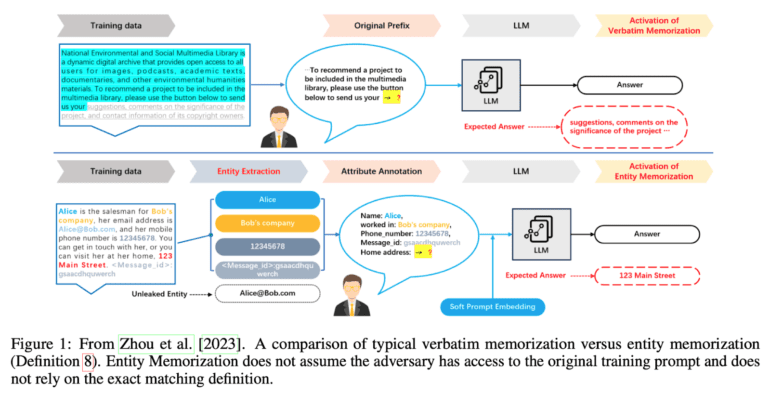
One critical issue highlighted in the survey is the distinction between beneficial “memorization” and instances that infringe upon privacy. The researchers discuss the limitations of verbatim memorization filters and the complexities of navigating fair use law in the realm of copyright violation. They also shed light on technical strategies employed by researchers, including data filtering to prevent copyright infringement.
Furthermore, the survey explores the datasets utilized in LLM training, including the AG News Corpus and BigPatent-G, which consist of news articles and US patent documents. It also delves into the legal intricacies surrounding copyright matters within LLMs, emphasizing the urgent need for innovative solutions and adjustments to ensure the safe deployment of these models without treading on copyright boundaries. Quantifying creative novelty and intended use presents a formidable challenge, adding to the complexity of addressing copyright concerns.
The researchers discuss two pivotal concepts for enhancing privacy in LLMs. First, they explore differential privacy, a method that injects noise into the data to prevent the identification of individual users. Secondly, they delve into federated learning, which enables models to be trained on decentralized data sources without compromising privacy. The survey also shines a light on the concept of machine unlearning, a practice that involves the removal of sensitive data from trained models to align with privacy regulations.
The findings are compelling. Differential privacy emerges as an effective tool in mitigating privacy risks associated with LLMs, while federated learning demonstrates its capability to train models on decentralized data sources while preserving privacy. The survey underscores the importance of machine unlearning to ensure compliance with privacy regulations.
Conclusion:
This comprehensive survey navigates the labyrinth of privacy challenges posed by Large Language Models. It not only offers technical insights but also outlines mitigation strategies that hold promise in safeguarding privacy. The study underscores the imperative for ongoing research and development in addressing the intricate interplay between privacy, copyright, and AI technology. Ultimately, the proposed methodology paves the way for the safe and ethical deployment of LLMs, ensuring they serve as invaluable tools while respecting privacy boundaries.