
- Eindhoven University of Technology has introduced Nerva, a new C++ neural network library designed for true sparsity.
- Nerva utilizes Intel’s Math Kernel Library (MKL) to perform sparse matrix operations, eliminating the need for binary masks.
- The library supports a Python interface, making it accessible for researchers using PyTorch and Keras.
- Nerva achieves significant memory savings by storing only non-zero entries, optimizing both runtime and memory efficiency.
- Compared to PyTorch, Nerva demonstrated up to four times faster runtime at 99% sparsity levels and a 49-fold reduction in memory usage.
- Nerva’s future updates will include GPU support to further enhance performance.
Main AI News:
Deep learning has revolutionized various scientific domains, revealing its vast potential through numerous applications. However, these advancements often come with high computational demands due to the large parameter sets of neural networks. Researchers have been actively seeking methods to optimize these models by reducing their size without degrading their performance. Among these methods, neural network sparsity has emerged as a pivotal strategy, aiming to enhance both efficiency and manageability.
One significant challenge in deep learning is the extensive computational and memory resources required by large networks. Traditional compression techniques, like pruning, reduce model size by eliminating certain weights based on specific criteria. Unfortunately, these methods are limited by retaining zeroed weights in memory, which undermines the full benefits of sparsity. This inefficiency underscores the need for more effective sparse implementations that optimize both memory and computational resources, surpassing the limitations of conventional techniques.
Current approaches to sparse neural networks often rely on binary masks, which only partially utilize the benefits of sparse computations. Even advanced techniques like Dynamic Sparse Training, which adapts network structure during training, still rely on dense matrix operations. Although libraries like PyTorch and Keras offer support for sparse models, they fall short in achieving true reductions in memory and computation time due to their reliance on binary masks. This indicates that the full potential of sparse neural networks remains largely untapped.
Eindhoven University of Technology has introduced Nerva, a groundbreaking neural network library developed in C++ that promises a genuinely sparse implementation. Utilizing Intel’s Math Kernel Library (MKL) for sparse matrix operations, Nerva eliminates the need for binary masks and enhances both training efficiency and memory usage. The library also provides a Python interface, making it accessible to researchers accustomed to frameworks like PyTorch and Keras. Nerva is designed with a focus on runtime efficiency, memory optimization, and accessibility, effectively addressing the needs of the research community.
Nerva significantly reduces the computational demands of neural networks by leveraging sparse matrix operations. Unlike traditional methods that store zeroed weights, Nerva retains only non-zero entries, leading to substantial memory savings. Initially optimized for CPU performance, future updates will include GPU support. Nerva’s efficient implementation of essential operations, such as sparse matrix multiplications, ensures that only non-zero values are computed, avoiding the need to store dense products in memory.
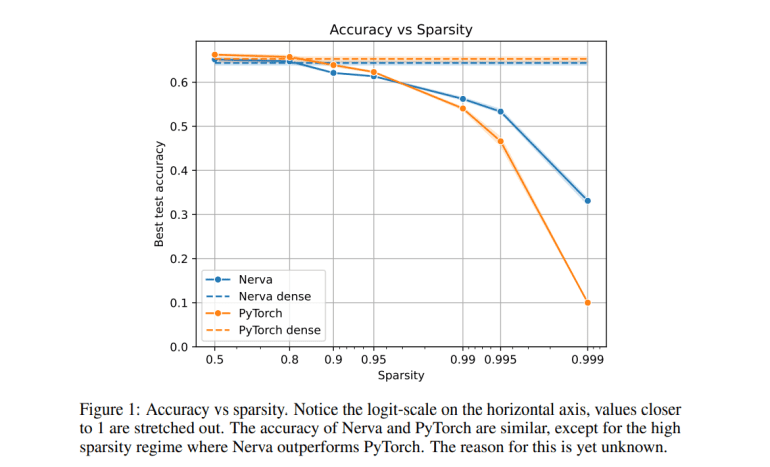
Performance tests of Nerva against PyTorch using the CIFAR-10 dataset revealed impressive results. Nerva exhibited a linear reduction in runtime as sparsity increased, outperforming PyTorch, particularly at high sparsity levels. For example, at a 99% sparsity level, Nerva cut runtime by a factor of four compared to PyTorch models using masks. Nerva matched PyTorch in accuracy while significantly accelerating training and inference times, and achieved a 49-fold reduction in memory usage for models with 99% sparsity. These findings underscore Nerva’s capability to offer efficient sparse neural network training without compromising performance.
Conclusion:
Nerva represents a significant advancement in sparse neural network technology, offering substantial improvements in computational efficiency and memory optimization. For the market, this development signifies a notable shift towards more effective utilization of resources in deep learning applications. Researchers and industry professionals will benefit from faster training times and reduced memory requirements, potentially accelerating the deployment of neural network models in various fields. This progress could lead to broader adoption of sparse neural networks, driving innovation and efficiency across the tech industry.