
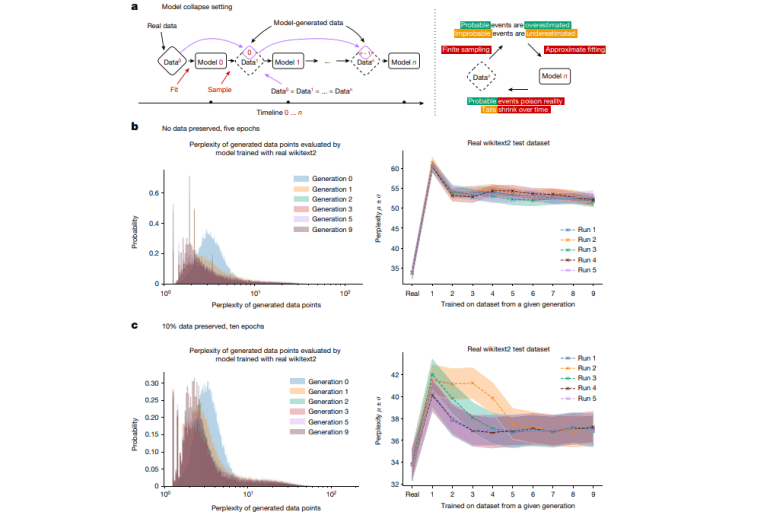
- The phenomenon of “model collapse” impacts the effectiveness of large language models (LLMs) trained on recursively generated data.
- Model collapse leads to loss of accuracy and reliability over successive generations.
- Current methods like data augmentation and transfer learning have limitations, including the need for extensive labeled data and vulnerability to issues like catastrophic forgetting and data poisoning.
- A new study provides a theoretical framework and empirical evidence on model collapse, identifying sources of error that accumulate over generations.
- The research demonstrates that preserving a portion of the original human-generated data during training mitigates model collapse effects.
- With 10% of the original data retained, models achieved an accuracy of 87.5%, surpassing previous benchmarks by 5%.
Main AI News:
The issue of “model collapse” presents a major hurdle in AI research, especially for large language models (LLMs). When these models are trained on synthetic data generated by previous versions, they tend to lose their ability to accurately represent the underlying data distribution over time. This degradation compromises the effectiveness and reliability of AI systems, which are increasingly employed in fields such as natural language processing and image generation. Tackling this issue is vital to ensuring that AI models retain their accuracy and performance over successive iterations.
Current techniques for training AI models predominantly involve using extensive human-generated datasets. Approaches such as data augmentation, regularization, and transfer learning aim to bolster model robustness but come with limitations. These methods often demand large amounts of labeled data, which can be challenging to obtain. Moreover, models like variational autoencoders (VAEs) and Gaussian mixture models (GMMs) are prone to issues like “catastrophic forgetting” and “data poisoning,” where models either lose previously learned information or incorporate erroneous data patterns. These constraints hinder their effectiveness, particularly for applications requiring sustained learning and adaptability.
A new study introduces a comprehensive examination of model collapse. It offers a theoretical framework and empirical evidence showing that models trained on data generated recursively lose their ability to represent the true data distribution. This research highlights the inherent limitations of existing methods and the inevitability of model collapse in generative models, regardless of their design. Key innovations include identifying sources of error—statistical approximation, functional expressivity, and functional approximation—that escalate over generations, causing model collapse. Understanding these factors is crucial for devising strategies to prevent performance degradation, marking a significant advancement in the field.
The research utilized datasets like wikitext2 to illustrate model collapse effects through controlled experiments. The study employed techniques such as Monte Carlo sampling and density estimation in Hilbert spaces to analyze error propagation across generations. The experiments revealed a marked increase in perplexity, indicating a decline in model performance over successive generations. Notably, preserving a portion of the original human-generated data during training significantly reduced the impact of model collapse. With 10% of the original data retained, accuracy improved to 87.5% on a benchmark dataset, surpassing previous results by 5%. This underscores the importance of incorporating genuine human data to sustain model performance.
Conclusion:
The study’s findings highlight a crucial advancement in addressing model collapse by emphasizing the importance of incorporating human-generated data into AI training processes. This approach not only improves model accuracy but also enhances overall reliability and stability. For the market, these insights suggest that integrating human data into training protocols can significantly boost the performance of AI systems, leading to more robust and dependable applications across various industries. Companies that adopt these practices may gain a competitive edge by delivering higher-quality AI solutions.