
TL;DR:
- NExT-GPT, an End-to-End General-Purpose Any-to-Any Multimodal Large Language Model (MM-LLM), represents a groundbreaking development in AI technology.
- Multimodal LLMs enable more natural and intuitive communication between users and AI systems, encompassing voice, text, and visual inputs.
- Challenges in training MM-LLMs include the need for extensive data and aligning data from different modalities.
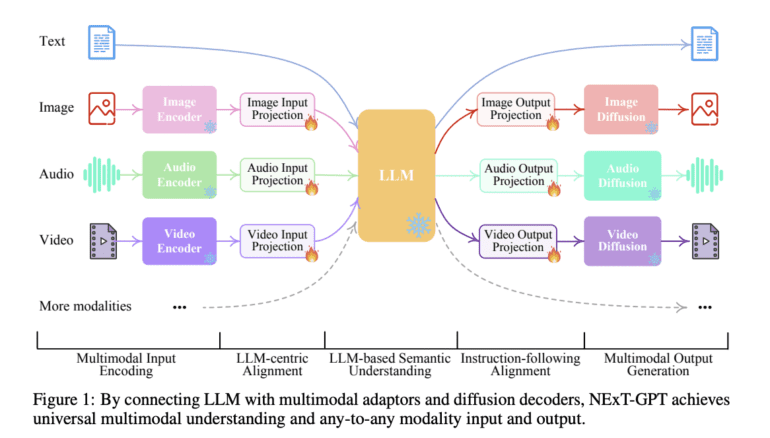
- NExT-GPT, developed by NeXT++ and NUS, tackles these challenges by handling input and output in any combination of text, image, video, and audio modalities.
- It modifies existing open-source LLMs for cost-effectiveness and leverages pre-trained encoders and decoders.
- NExT-GPT introduces lightweight alignment learning techniques and modality-switching instruction tuning (MosIT) for improved cross-modal understanding and content generation.
- A high-quality dataset is created to train NExT-GPT, offering complexity and variability for diverse user interactions.
Main AI News:
In the ever-evolving realm of artificial intelligence, breakthroughs that enhance human-computer interaction are highly coveted. Enter NExT-GPT, a groundbreaking End-to-End General-Purpose Any-to-Any Multimodal Large Language Model (MM-LLM) developed by the visionary researchers at NeXT++ and the School of Computing at NUS.
Multimodal LLMs represent a significant stride forward, as they facilitate more natural and intuitive communication between users and AI systems, seamlessly accommodating voice, text, and visual inputs. The implications of this innovation are vast, ranging from more contextually relevant chatbots and virtual assistants to precision-driven content recommendation systems. These MM-LLMs build upon the foundational prowess of traditional unimodal language models, such as GPT-3, while also embracing additional capabilities to handle a plethora of data types.
However, like any groundbreaking technology, there are challenges to overcome. Multimodal LLMs demand a substantial amount of data to perform at their peak, rendering them less sample-efficient than their AI counterparts. One of the critical challenges lies in aligning data from different modalities during the training process. The absence of a holistic end-to-end training approach hampers the propagation of errors and limits content understanding and multimodal generation capabilities. Given that information transfer across different modules hinges entirely on discrete texts generated by the LLM, the inevitability of noise and errors looms large. Ensuring the synchronization of information from each modality becomes imperative for effective training.
To combat these formidable challenges, NeXT++ and NUS have birthed NExT-GPT. This MM-LLM is a marvel, designed to seamlessly handle input and output in any combination of text, image, video, and audio modalities. It empowers encoders to process inputs across various modalities, which are then seamlessly integrated into the LLM’s core representations.
The methodology employed is a stroke of brilliance. By modifying an existing open-source LLM as the core information processor, NExT-GPT offers a cost-effective solution. It leverages the pre-trained high-performance encoders and decoders, including Q-Former, ImageBind, and state-of-the-art latent diffusion models, avoiding the need to start from scratch.
One of the standout features of NExT-GPT is its lightweight alignment learning technique. This technique streamlines LLM-centric alignment on the encoding side and instruction-following alignment on the decoding side, requiring minimal parameter adjustments for optimal semantic alignment. Moreover, the introduction of modality-switching instruction tuning (MosIT) endows this MM-LLM with remarkable cross-modal understanding and reasoning abilities, enabling the generation of sophisticated multimodal content. This ingenious feature bridges the gap between the feature spaces of different modalities, ensuring a seamless understanding of diverse inputs and robust alignment learning.
To fortify the capabilities of NExT-GPT, the researchers painstakingly constructed a high-quality dataset encompassing a wide array of multimodal inputs and outputs. This dataset serves as the bedrock, providing the complexity and variability necessary for training MM-LLMs to handle diverse user interactions and deliver precisely tailored responses.
Conclusion:
NExT-GPT signifies a remarkable leap in AI capabilities, bridging the gap between various modalities and paving the way for more human-like AI systems. This innovation holds the potential to revolutionize markets by enabling advanced chatbots, virtual assistants, and content recommendation systems that can provide contextually relevant and comprehensive responses, transforming the way businesses interact with their customers and users. It also presents opportunities for companies to harness the power of multimodal AI for enhanced customer engagement and personalized experiences.