
TL;DR:
- Notus, a fine-tuned version of Data Preference Optimization (DPO), aims to enhance language models by focusing on high-quality data curation.
- Zephyr 7B Beta’s success with DPO laid the foundation for Notus, which takes a different approach to data curation.
- Notus leverages the UltraFeedback dataset, evaluating responses using GPT-4 and average preference ratings for a more refined selection process.
- Notus’ rigorous curation process ensures superior alignment of responses with user preferences.
- Notus seeks to reiterate response generation and AI ranking, applying dDPO on top of dSFT fine-tuning.
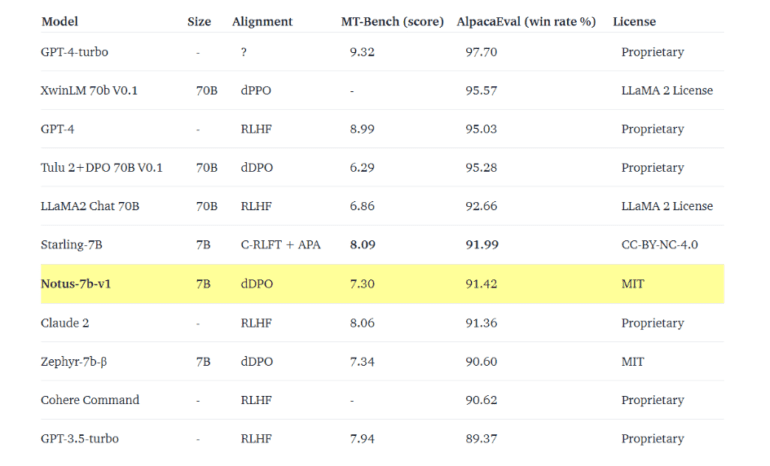
- Notus achieves impressive results, nearly matching Zephyr on MT-Bench and outperforming competitors on AlpacaEval.
- In the future, Notus and Argilla plan to contribute open-source models while continually improving data quality.
Main AI News:
In the relentless pursuit of refining language models, a new contender emerges – Notus. Building upon the foundation laid by Zephyr, Notus, a fine-tuned version of Data Preference Optimization (DPO), places a strong emphasis on the meticulous curation of high-quality data to enhance the process of response generation.
The recent release of Zephyr 7B Beta marked a significant step towards creating a more compact yet intent-aligned Language Model (LLM). This achievement was made possible through a methodology that involved distilled Supervised Fine-Tuning (dSFT), followed by distilled Direct Preference Optimization (dDPO), utilizing AI Feedback (AIF) datasets such as UltraFeedback.
What sets Zephyr 7B Beta apart from its larger counterparts, like Llama 2 Chat 70B, is its effective application of DPO after SFT. This strategic move catapulted Zephyr ahead of the competition, and Notus aims to build upon this success by adopting a distinct approach to data curation for superior model fine-tuning.
The core of Notus lies in its utilization of the same data source as Zephyr – openbmb/UltraFeedback. However, Notus takes a different path, prioritizing the cultivation of high-quality data through rigorous curation. Within the UltraFeedback dataset, responses were evaluated using GPT-4 and assigned scores across preference areas, including instruction-following, truthfulness, honesty, and helpfulness. Each response also came with rationales and an overall critique score.
Remarkably, while Zephyr relied on the overall critique score to determine selected responses, Notus opted to analyze the average preference ratings. Surprisingly, in approximately half of the cases, the highest-rated response based on average preference ratings diverged from the one chosen using the critique score.
To curate a dataset conducive to DPO, Notus meticulously calculated the average preference ratings and selected the response with the highest average as the chosen one. This stringent curation process was designed to bolster the quality of the dataset and ensure a more precise alignment of responses with user preferences.
Notus has set its sights on reiterating both the response generation and AI ranking stages, while retaining the dSFT stage as it is. It then applies dDPO on top of the previously dSFT fine-tuned version of Zephyr, with a primary focus on comprehending and exploring the AIF data and experimenting with that concept.
The results speak for themselves. Notus demonstrated impressive efficacy, nearly matching Zephyr on MT-Bench while outperforming Zephyr, Claude 2, and Cohere Command on AlpacaEval. This solidified its position as one of the most competitive 7B commercial models in the market.
As we look forward, Notus, along with its dedicated developers at Argilla, remains unwavering in their commitment to a data-centric approach. They are actively crafting an AI Feedback (AIF) framework to collect feedback generated by LLMs, with the aspiration of creating high-quality synthetic labeled datasets similar to UltraFeedback. Their mission extends beyond enhancing in-house LLMs; they aim to contribute open-source models to the community while continuously elevating data quality for superior language model performance.
Conclusion:
Notus’ innovative approach to data-driven refinement has significant implications for the language model market. Its success demonstrates the importance of meticulous data curation in achieving superior model performance. As language models continue to evolve, the focus on high-quality data will likely become a key competitive advantage, shaping the future of AI-driven language technologies.