
- NVIDIA introduces Nemotron-4 340B, a set of models aimed at producing synthetic data for training large language models in various industries.
- The series includes base, instruct, and reward models, all optimized for use with NVIDIA NeMo and NVIDIA TensorRT-LLM.
- Developers can access Nemotron-4 340B via Hugging Face and soon on ai.nvidia.com.
- Models utilize tensor parallelism for efficient, scalable inference.
- The Nemotron-4 340B Base model is customizable for specific industry applications, leveraging extensive pretraining data.
- Customization options include supervised fine-tuning and low-rank adaptation, with tools like NeMo Aligner available for further refinement.
- The Nemotron-4 340B Instruct model has been extensively safety-tested, yet users are advised to review outputs thoroughly.
- Information on model security and further details can be found on the model card, with foundational research available for review.
Main AI News:
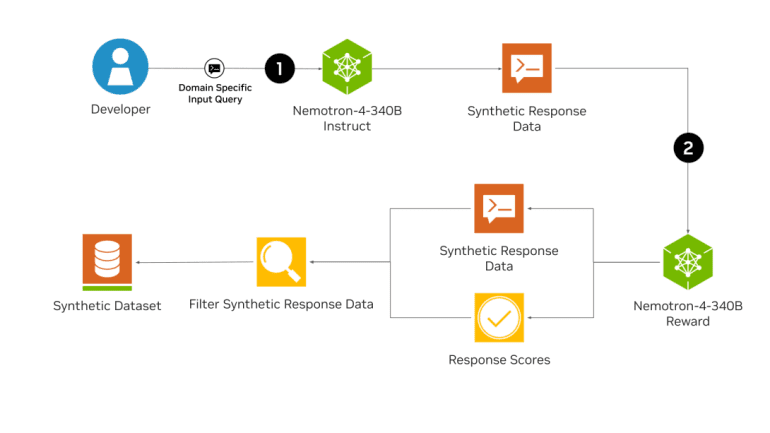
Development NVIDIA has launched the Nemotron-4 340B, a sophisticated series of models crafted to create synthetic data for the training of large language models (LLMs) across diverse sectors such as healthcare, finance, manufacturing, and retail, as detailed on the NVIDIA Blog. The Nemotron-4 340B suite encompasses base, instruct, and reward models, all fine-tuned to integrate seamlessly with NVIDIA NeMo and NVIDIA TensorRT-LLM. This integration forms a comprehensive system for producing and refining synthetic data essential for LLM training. Developers have the option to acquire Nemotron-4 340B through Hugging Face, with future availability projected on ai.nvidia.com.
Leveraging cutting-edge open-source frameworks like NVIDIA NeMo and NVIDIA TensorRT-LLM, developers are empowered to enhance the performance of their instruct and reward models for synthetic data creation and response evaluation. All variants of the Nemotron-4 340B are tailored with TensorRT-LLM to utilize tensor parallelism, ensuring scalable and efficient inference.
The Nemotron-4 340B Base model, trained using 9 trillion tokens, offers customization via the NeMo framework to cater to specific scenarios or sectors. This customization leverages a robust pretraining regimen, improving the precision of outputs for targeted downstream applications. Available customization techniques through NeMo encompass supervised fine-tuning and efficiency-oriented methods like low-rank adaptation (LoRA). Further model refinement is achievable with tools like NeMo Aligner and datasets marked by Nemotron-4 340B Reward, enhancing the relevance and accuracy of outputs.
The Nemotron-4 340B Instruct model has been rigorously tested for safety, undergoing adversarial assessments and demonstrating robustness across various risk metrics. Despite these precautions, it is advised that users conduct thorough reviews of the model’s outputs to confirm their appropriateness, safety, and accuracy for intended applications. Detailed insights into model security and safety evaluations are accessible through the model card. The Nemotron-4 340B range is available for download via Hugging Face, and those interested in the foundational technology can consult the associated research documentation.
Conclusion:
NVIDIA’s launch of the Nemotron-4 340B models signifies a pivotal development in the realm of synthetic data generation, particularly for training large language models. This move not only broadens the capabilities of developers in fine-tuning AI applications across various sectors but also enhances the efficiency and accuracy of AI model training through advanced customization options. The introduction of such a versatile toolset is poised to drive innovation and elevate competitive dynamics within the AI technology market, providing NVIDIA with a strategic advantage in terms of market share and influence within the AI development community.