
- NVIDIA introduces Nemotron-4 15B, a 15-billion-parameter large multilingual language model trained on 8 trillion tokens.
- The model adeptly bridges linguistic barriers and programming logic, catering to global audiences and diverse coding tasks.
- Nemotron-4 15B’s innovative training methodology, incorporating Rotary Position embedding and SentencePiece tokenizer, ensures efficient learning and comprehensive coverage.
- In performance evaluations, Nemotron-4 15B outshines larger models and specialized counterparts, demonstrating superior proficiency across languages and coding tasks.
- Its exceptional performance signifies a new era of AI applications, promising enhanced global communication, accessible coding education, and enriched human-machine interactions.
Main AI News:
AI research endeavors to equip models with human language and coding proficiency, fostering seamless human-machine interactions on a global scale. The quest for such advanced capabilities faces the challenge of bridging linguistic diversity and programming logic, demanding nuanced understanding across languages and code structures.
Overcoming this challenge necessitates extensive training on diverse datasets encompassing multiple languages and coding paradigms. NVIDIA’s Nemotron-4 15B emerges as a breakthrough solution, boasting a colossal 15-billion-parameter model trained on a staggering 8 trillion tokens. This model transcends linguistic barriers and code complexities, setting new benchmarks for multilingual understanding and programming proficiency.
Nemotron-4 15B’s innovation extends beyond its scale; its training methodology stands as a testament to meticulous engineering. Leveraging a standard decoder-only Transformer architecture enhanced with Rotary Position embedding and a SentencePiece tokenizer, Nemotron-4 15B optimizes understanding and generation capabilities. This strategic amalgamation of architecture and data processing minimizes redundancy and maximizes coverage, ensuring efficient learning across a spectrum of languages and code syntaxes.
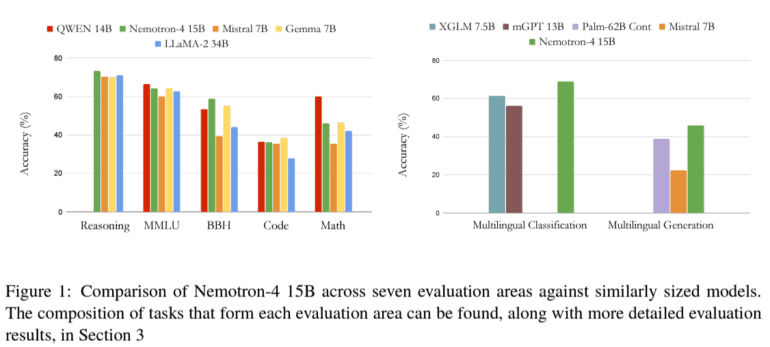
In performance evaluations, Nemotron-4 15B eclipses its counterparts. Across English comprehension, coding tasks, and multilingual benchmarks, it showcases unparalleled proficiency. Outperforming larger models and specialized counterparts, Nemotron-4 15B demonstrates superior accuracy, especially in coding tasks and low-resource languages. Notably, its performance in multilingual evaluations sets a new standard, boasting significant improvements over existing models.
This exceptional performance underscores Nemotron-4 15B’s leadership in general-purpose language understanding and specialized applications. NVIDIA’s model heralds a new era of AI applications, promising enhanced global communication, accessible coding education, and enriched human-machine interactions across diverse linguistic and cultural landscapes. The meticulous training methodology and outstanding performance of Nemotron-4 15B highlight the transformative potential of large language models, heralding an era of inclusive and effective technology interactions globally.
Conclusion:
NVIDIA’s Nemotron-4 15B signifies a groundbreaking advancement in AI models, promising transformative impacts on global communication, coding education, and technology interactions. Its superior performance and multilingual proficiency position it as a frontrunner in the market, paving the way for inclusive and effective technology applications worldwide.