
- A recent shift in machine learning embraces diverse data distributions for enhanced model performance.
- “Rich representations” surpass traditional methods, adapting models to varied data sources.
- NYU and Facebook AI Research pioneers high dropout rates for out-of-distribution (OOD) excellence.
- Fine-tuning pre-trained models with substantial dropout rates outshines ensemble techniques.
- Linear training approximation and leveraging existing representations highlight method efficacy.
- Substantial gains in OOD performance across benchmarks, notably on VLCS dataset.
- The method promises to enhance model robustness and reliability across diverse datasets.
Main AI News:
In the realm of machine learning, a notable departure has occurred in recent times from the notion that training and testing data stem from identical distributions. Scholars have discerned that models exhibit superior performance when confronted with data from diverse distributions. This adaptability is frequently attained through what is termed as “rich representations,” surpassing the capabilities of models trained under conventional sparsity-inducing regularization or standard stochastic gradient methods.
The pivotal challenge lies in optimizing machine learning models to excel across a spectrum of distributions, not limited to the one they were originally trained on. Models have undergone fine-tuning on expansive, pre-trained datasets tailored to a specific task and subsequently evaluated on a suite of tasks devised to assess various facets of the system. Nevertheless, this approach encounters limitations, particularly in the face of data distributions diverging from the training set.
Scholars have delved into diverse methodologies to procure versatile representations, encompassing the engineering of varied datasets, architectures, and hyperparameters. Encouraging outcomes have been attained through the adversarial reweighting of the training dataset and the amalgamation of representations from multiple networks. Fine-tuning deep residual networks emerges as an almost linear process, with the ultimate training phase confined to a nearly convex attraction basin.
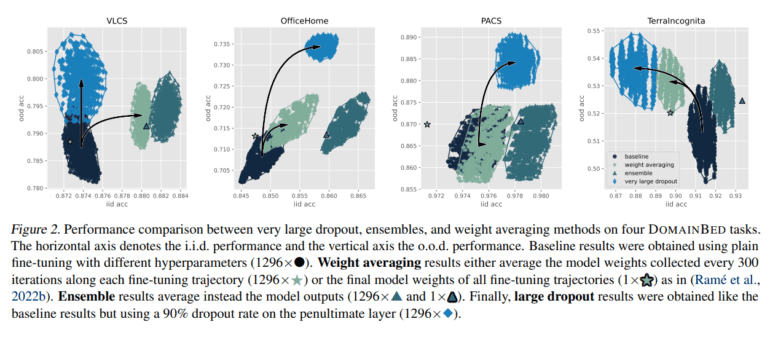
Researchers hailing from New York University and Facebook AI Research have introduced a groundbreaking methodology aimed at achieving out-of-distribution (OOD) performance. They delve into the utilization of exceedingly high dropout rates as a substitute for ensemble techniques to acquire rich representations. Traditionally, training a deep network from scratch with high dropout rates proves arduous owing to the complexity and depth of the network. Nonetheless, fine-tuning a pre-trained model under such conditions is viable and outstrips the performance attained by ensembles and weight-averaging methods akin to model soups.
The approach entails a sophisticated fine-tuning process on a deep learning network featuring residual connections, primarily trained on extensive datasets. This process is distinguished by the application of very high dropout rates to the penultimate layer during fine-tuning, effectively impeding contributions from all residual blocks sans engendering new representations, thereby leveraging existing ones. The technique garners attention by leveraging a linear training approximation, where dropout application serves as a form of gentler regularization compared to its usage in non-linear systems. Notably, this approach yields comparable or superior performance to traditional methods such as ensembles and weight averaging, thereby showcasing its efficacy across diverse DOMAINBED tasks.
The performance outcomes accentuate the efficacy of this methodology. Fine-tuning with substantial dropout rates augmented OOD performance across several benchmarks. For instance, on the VLCS dataset, a domain adaptation benchmark posing substantial challenges for generalization, models fine-tuned with this approach exhibited noteworthy enhancements. The findings herald a significant stride in OOD performance, attesting to the method’s potential in bolstering model robustness and reliability across varied datasets.
Conclusion:
The research conducted by NYU and Facebook AI Research unveils a paradigm shift in machine learning, demonstrating the efficacy of high dropout rates for achieving rich representations and enhancing out-of-distribution performance. This innovation not only promises to bolster model robustness and reliability across diverse datasets but also suggests a transformative potential for the market, offering more efficient and adaptable machine learning solutions tailored to the challenges of varied data distributions.