
- OpenVoice V2 redefines Text-to-Speech (TTS) synthesis with Instant Voice Cloning (IVC).
- It offers enhanced style control, including emotion and accent modulation, without reliance on reference speakers.
- The model enables seamless cross-lingual voice cloning across major languages.
- Innovations like Accurate Tone Color Cloning and Flexible Voice Style Control ensure precise voice replication.
- OpenVoice V2 achieves rapid inference speeds, with 12× real-time performance on standard hardware.
Main AI News:
In the dynamic realm of Text-to-Speech (TTS) synthesis, Instant Voice Cloning (IVC) stands as a pivotal innovation, streamlining the replication of diverse vocal personas with utmost efficiency. Traditional methodologies such as VALLE and XTTS have paved the way, yet their limitations in style modulation persist. Auto-regressive models, albeit effective, grapple with computational demands, while non-autoregressive alternatives like YourTTS and Voicebox sacrifice style finesse for speed. Meanwhile, the pursuit of cross-lingual voice cloning encounters barriers of dataset availability and closed-source frameworks, stymying collaborative progress.
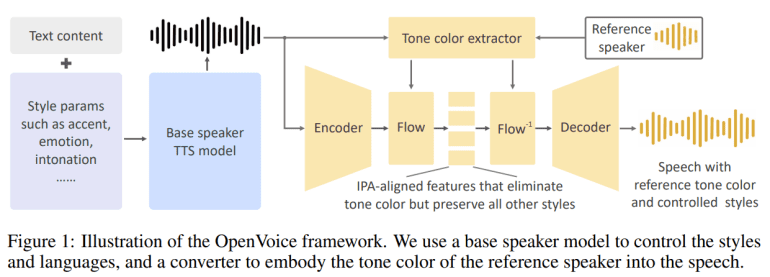
Enter OpenVoice V2, a collaborative effort by MIT CSAIL, MyShell.ai, and Tsinghua University researchers, heralding a new era in TTS technology. This groundbreaking model transcends linguistic confines, empowering applications ranging from tailored digital interactions to seamless multilingual dubbing. With its refined audio fidelity and native support for six major languages, OpenVoice V2 eclipses its forerunner by offering unparalleled control over voice nuances. Emotion, accent, and rhythm become malleable parameters under its adept manipulation, all without tethering to a reference speaker’s style.
Building upon prior research, OpenVoice V2 orchestrates a symphony of innovations: Accurate Tone Color Cloning, Flexible Voice Style Control, and Zero-shot Cross-lingual Voice Cloning. Its architecture embodies simplicity through the separation of tone color cloning from style and language modulation, achieved via distinct modules for TTS and tone color conversion. Training regimens focus on data acquisition for each component independently, culminating in a seamless fusion during synthesis. Notably, flow layers ensure natural tonal transitions while upholding linguistic fidelity, facilitating fluid multilingual expression.
The assessment of voice cloning methodologies encounters a maze of subjectivity, exacerbated by variations in datasets and evaluation metrics. OpenVoice tackles this challenge head-on, prioritizing qualitative analysis over numerical benchmarks. Publicly available audio samples serve as litmus tests, validating the model’s prowess in tone color replication, style fidelity, and cross-lingual adaptability. Furthermore, its streamlined architecture affords blazingly fast inference speeds, attaining a remarkable 12× real-time performance on standard hardware—a testament to its efficiency and scalability potential.
Conclusion:
OpenVoice V2’s breakthrough advancements in multilingual voice cloning and style precision herald a paradigm shift in the TTS market. Its seamless cross-lingual capabilities and refined control over voice nuances not only cater to diverse linguistic needs but also pave the way for innovative applications across industries, from personalized digital interactions to automated dubbing solutions. As efficiency benchmarks are shattered and accessibility to advanced voice synthesis technologies expands, businesses can anticipate heightened levels of engagement, efficiency, and creativity in their audio-based endeavors.