
TL;DR:
- AutoMix optimizes queries to Large Language Models (LLMs) using self-verification and meta-verification.
- It prioritizes context over LLM knowledge, enhancing accuracy without extensive training.
- The iterative model-switching method streamlines query handling for efficiency.
- A few-shot self-verification process and meta-verifier categorize queries for improved routing.
- AutoMix significantly boosts IBC performance, outperforming traditional methods.
- Its versatility makes it suitable for various scenarios and domains.
- Future research can explore its adaptability and potential refinements.
Main AI News:
In today’s fast-paced business landscape, maximizing the efficiency of language processing tasks is paramount. Enter AutoMix, an innovative solution that redefines the way we leverage Large Language Models (LLMs) from the cloud. This cutting-edge approach focuses on optimizing the allocation of queries to LLMs by evaluating the accuracy of responses from smaller language models. Let’s delve into how AutoMix achieves this optimization and its implications for computational cost and performance.
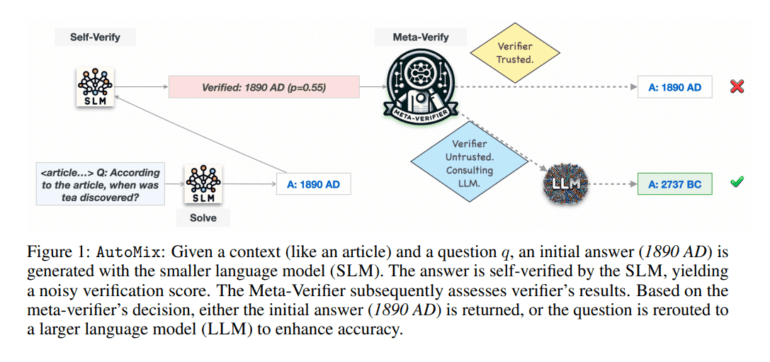
AutoMix takes a unique approach to information verification compared to traditional methods. Instead of relying solely on LLM knowledge, it prioritizes context to ensure accuracy. This is made possible through a few-shot self-verification mechanism and a meta-verifier that assesses the reliability of its outputs, all without the need for extensive training. This emphasis on context and robust self-verification aligns perfectly with the principles of conformal prediction. Unlike other approaches that demand verifier training or architectural modifications, AutoMix offers flexibility between models, requiring only black-box access to APIs.
The heart of AutoMix lies in its iterative model-switching method. It intelligently queries models of varying sizes and capabilities, performing feedback verification at each step to decide whether to accept the output or switch to a more capable model. What’s remarkable is that this approach doesn’t necessitate separate models or access to model weights and gradients; instead, it harnesses the power of black-box language model APIs. By introducing few-shot learning and self-verification into solution generation, verification, and model switching, AutoMix streamlines the process for greater efficiency and effectiveness.
AutoMix’s few-shot self-verification process is a game-changer in assessing output reliability without the need for extensive training. Pair that with the power of a meta-verifier, and you have a winning combination. The system categorizes queries into three buckets: Simple, Complex, or Unsolvable, using a Partially Observable Markov Decision Process (POMDP) framework. This intelligent routing of queries to larger language models based on approximate output correctness from smaller models is what sets AutoMix apart. It’s quantified by the Incremental Benefit Per Unit Cost (IBC) metric, showcasing how effectively it combines smaller and larger language models to optimize computational cost and performance in language processing tasks.
Through context-driven reasoning, AutoMix has significantly boosted IBC (Intentional Behaviour Change) performance, surpassing baseline methods by an impressive margin of up to 89% across five datasets. The inclusion of a meta-verifier consistently demonstrates superior IBC performance, especially in the LLAMA2-1370B datasets. The standout performer in three out of five datasets is AutoMix-POMDP, delivering substantial improvements in most cases. It maintains a positive IBC across all evaluated costs, indicating a consistent track record of enhancements. The POMDP-based meta-verifier within AutoMix has also proven its mettle by outperforming Verifier-Self-Consistency by up to 42% across all datasets.
AutoMix isn’t just a promising concept; it’s a framework that seamlessly integrates black-box LLM APIs into a multi-step problem-solving approach. Its self-verification and context-driven few-shot verification strike a perfect balance between performance and computational cost, making it a versatile choice for various scenarios. Additionally, the incorporation of a POMDP within AutoMix enhances the accuracy of the few-shot verifier, hinting at its potential to elevate LLM performance during inference. All in all, AutoMix emerges as a powerful tool for language processing tasks that promises remarkable capabilities.
Looking ahead, future research can explore AutoMix’s applicability across diverse domains and tasks, assessing its adaptability. The evaluation of AutoMix’s performance with a wide range of language model combinations is imperative to ensure scalability to larger models. The refinement of the few-shot self-verification mechanism, possibly incorporating contextual or external information, holds the promise of improved accuracy. Furthermore, the exploration of alternative meta-verifiers or verification techniques can unlock even more potential within AutoMix. Real-world user studies are a must to gauge AutoMix’s practical usability and user satisfaction in real-world scenarios. As we step into an era driven by AI-powered language processing, AutoMix stands as a beacon of innovation, ready to reshape the landscape of computational efficiency.
Conclusion:
AutoMix’s innovative approach to optimizing language models presents a significant opportunity in the market. By balancing efficiency and accuracy through self-verification, context prioritization, and intelligent query routing, AutoMix can revolutionize language processing tasks across diverse industries. Its proven performance improvements and adaptability make it a promising solution, with potential applications in numerous domains. As businesses increasingly rely on AI-driven language processing, AutoMix’s capabilities can provide a competitive edge and drive market growth.