
- Training large-scale language models is challenging due to increasing computational costs and energy consumption.
- Adam optimizer is known for adaptive learning rate capabilities, while SGD is simpler but less stable across hyperparameters.
- Adafactor is memory-efficient but sometimes underperforms compared to Adam; Lion shows promise but needs further validation.
- Harvard and Kempner Institute researchers compared Adam, SGD, Adafactor, and Lion across various model sizes and hyperparameters.
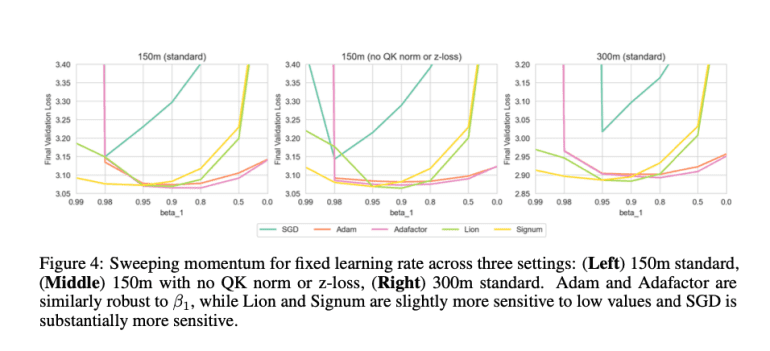
- Findings show Adam, Adafactor, and Lion perform similarly in both performance and stability, with SGD consistently underperforming.
- Adaptivity is crucial for the last layer and LayerNorm parameters; simpler methods like SGD can suffice for other model layers.
Main AI News:
Training large-scale language models poses substantial challenges, particularly with rising computational demands and energy consumption as model sizes expand. This issue is pivotal for advancing AI research, as optimizing training efficiency facilitates the development and deployment of sophisticated language models without prohibitive resource demands. Enhanced optimization methods can significantly boost the performance and applicability of AI models across diverse real-world applications such as medical diagnostics and automated customer service.
Various methods currently exist for optimizing language models, with the Adam optimizer standing out for its adaptive learning rate capabilities. Additionally, optimizers like Stochastic Gradient Descent (SGD), Adafactor, and Lion have also been explored. However, each method carries its own set of limitations. For example, while SGD is computationally simpler, it lacks the adaptive features of Adam, resulting in less stable performance across different hyperparameters. Adafactor, though more memory-efficient, sometimes falls short of Adam in terms of overall performance. Lion, a newer entrant, shows promise but requires further validation across different model scales and architectures to establish its efficacy comprehensively.
A collaborative effort between researchers from Harvard University and the Kempner Institute at Harvard proposes a comparative analysis of several optimization algorithms, including Adam, SGD, Adafactor, and Lion. This study aims to assess their performance across various model sizes and hyperparameter configurations comprehensively. A key innovation lies in evaluating these optimizers not only based on peak performance but also on their stability under different hyperparameter settings. This dual focus addresses a critical gap in existing research, offering a nuanced understanding of each optimizer’s strengths and weaknesses.
The study introduces two simplified variants of Adam: Signum, which leverages Adam’s momentum benefits, and Adalayer, which isolates the effects of layerwise preconditioning. Experimentation involves extensive testing using autoregressive language models with varying parameter scales (150m, 300m, 600m, and 1.2b). Key hyperparameters such as learning rates and momentum are systematically adjusted to gauge their impact on optimizer performance. The models are trained on the C4 dataset, employing the T5 tokenizer, and evaluated based on validation loss. Detailed analyses delve into specific aspects of network architecture, including the role of LayerNorm parameters and the last layer in influencing overall model stability and performance. These analyses shed light on how different layers of the network respond to various optimization strategies.
Findings from the research indicate comparable performance and stability among Adam, Adafactor, and Lion, while SGD consistently lags behind. This suggests that practitioners can select optimizers based on practical considerations such as memory usage and implementation ease, without sacrificing significant performance. Importantly, the study underscores the critical role of adaptivity, particularly for the last layer and LayerNorm parameters, while simpler methods like SGD can effectively train the remainder of the model. This nuanced understanding of optimizer performance across diverse hyperparameters and model scales provides valuable insights for optimizing large-scale language models.
Conclusion:
This comparative study underscores the importance of choosing the right optimizer based on practical needs like memory efficiency and ease of implementation. For the market, it highlights that while newer optimizers like Lion show promise, established methods like Adam remain robust choices for optimizing large-scale language models. Understanding the nuanced performance differences across different optimizers and model configurations provides valuable insights for enhancing AI model efficiency in real-world applications.