
TL;DR:
- Orion-14B, a multilingual language model by Orion Star, boasts 14 billion parameters and 2.5 trillion tokens from languages like Chinese, English, Japanese, and Korean.
- The framework includes specialized models like Orion-14B-Chat-RAG and Orion-14B-Chat-Plugin for specific tasks.
- Exceptional adaptability and efficiency improvements, with a 70% reduction in model size and 30% faster inference.
- Outperforms competitors at the 20-billion parameter scale, excelling in comprehensive evaluations, particularly in Japanese and Korean.
- Rich multilingual dataset with a focus on English and Chinese, covering a wide range of topics.
- Orion-14B series represents a significant milestone in multilingual large language models.
Main AI News:
In the era of rapid AI advancements, large language models are becoming indispensable across various industries. These models, powered by extensive training datasets, are revolutionizing natural language processing (NLP) applications, including dialogue systems, machine translation, and information retrieval. The realm of Large Language Models (LLMs) has witnessed continuous innovation and evolution, giving rise to the Orion-14B framework.
Orion-14B, developed by the visionary team at Orion Star, represents a paradigm shift in the world of language models. The cornerstone of this framework is the Orion-14B-Base model, boasting a staggering 14 billion parameters and trained on an astounding 2.5 trillion tokens drawn from languages like Chinese, English, Japanese, and Korean. Notably, Orion-14B offers an impressive 200,000-token context length, setting a new standard in multilingual language modeling.
Diverse Models for Specific Tasks
Orion-14B is a comprehensive ecosystem comprising specialized models tailored to distinct tasks. Among them, Orion-14B-Chat-RAG shines as a fine-tuned gem, excelling in retrieval augmented generation tasks. Additionally, Orion-14B boasts the innovative Orion-14B-Chat-Plugin, designed for agent-related scenarios where the LLM operates seamlessly as a plugin and function call system. The framework extends further to encompass various application-oriented models, including long context models and quantized models, each optimized for specific use cases.
Adaptability and Excellence
The research team behind Orion-14B underscores the adaptability and exceptional performance of the series in human-annotated blind tests. Notably, the long-chat version of Orion-14B exhibits remarkable capabilities, effortlessly handling lengthy texts and accommodating up to 320,000 tokens. The quantized versions of Orion-14B have ushered in unparalleled efficiency improvements, reducing model size by an impressive 70% while boosting inference speed by 30%. Remarkably, this optimization comes with a negligible performance loss of less than 1%.
Outperforming the Competition
Orion-14B stands as a testament to its prowess, outperforming other models at the 20-billion parameter scale. It excels in comprehensive evaluations and demonstrates robust multilingual capabilities, particularly surpassing expectations in Japanese and Korean test sets. This superiority underscores its potential to redefine the landscape of large language models.
A Multilingual Treasure Trove
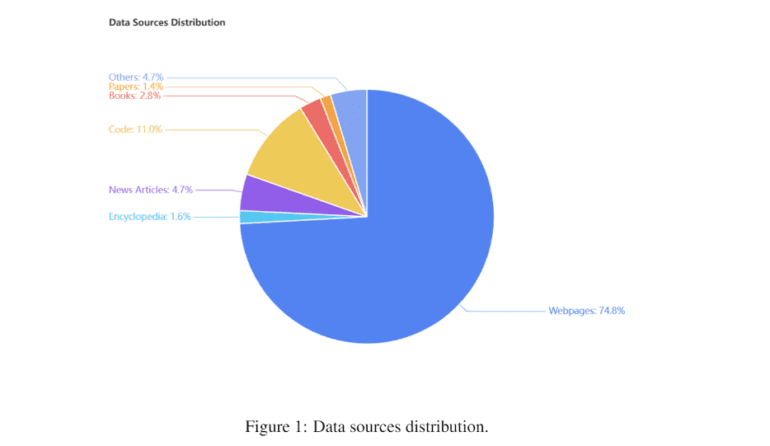
The dataset underpinning Orion-14B is a treasure trove of multilingual texts, with a strong focus on English and Chinese, constituting a significant 90% of the dataset. Efforts are also underway to incorporate Japanese and Korean texts, accounting for more than 5% of the content. The remaining portion of the dataset encompasses texts in diverse languages, including Spanish, French, German, Arabic, and more. This rich collection spans a wide range of topics, from web pages and news articles to encyclopedic entries, books, source code, and academic publications.
Overcoming Challenges for a Bright Future
The journey to develop the Orion-14B series was not without its challenges. However, in conclusion, it emerges as a monumental milestone in the realm of multilingual large language models. It not only outshines existing open-source models but also serves as a robust foundation for future LLM research. The Orion-14B research team is committed to further enhancing the efficiency and capabilities of this exceptional framework, ensuring its continued impact on the world of language models.
Conclusion:
Orion-14B’s emergence signals a transformative shift in the language model market. Its adaptability, efficiency gains, and superior performance position it as a formidable player, offering businesses unprecedented language processing capabilities across multiple languages. This development sets a new standard and opens doors to innovative applications, making Orion-14B a powerful asset in the evolving landscape of AI-powered business solutions.