
TL;DR:
- Osprey enhances Multimodal Large Language Models (MLLMs) by achieving pixel-level vision-language alignment.
- MLLMs bridge the gap between visual perception and language comprehension, which is crucial for AI applications.
- Current MLLMs excel at general image understanding but struggle with granular analysis of specific image regions.
- Osprey combines a CLIP backbone with a mask-aware visual extractor for unparalleled accuracy.
- It excels in open-vocabulary recognition, object classification, and detailed region description.
- Osprey revolutionizes the AI market by enabling precise image analysis for diverse applications.
Main AI News:
In the ever-evolving landscape of artificial intelligence, Multimodal Large Language Models (MLLMs) stand at the forefront, revolutionizing the synergy between visual and linguistic elements. These models represent a quantum leap in the realm of AI optical assistants, harnessing the power to decipher and synthesize information from both textual and visual inputs. Their evolution signifies a pivotal moment in the journey of AI, bridging the chasm between visual perception and linguistic comprehension. The intrinsic value of MLLMs lies in their unparalleled ability to process and grasp multimodal data, a critical component of AI’s application across diverse domains, including robotics, automated systems, and intelligent data analysis.
Yet, as the field of MLLMs advances, a central challenge looms large: the imperative need for precise vision-language alignment, especially at the pixel level. While current MLLMs proficiently interpret images at a broader, more generalized level using image-level or box-level understanding, they fall short when confronted with tasks demanding a granular and detailed analysis of specific image regions. This limitation hinders their effectiveness in applications requiring intricate and precise image comprehension, such as medical imaging analysis, intricate object recognition, and advanced visual data interpretation.
The prevailing methodologies in MLLMs predominantly revolve around employing image-text pairs for vision-language alignment, ideally suited for general image comprehension tasks. However, they lack finesse when it comes to region-specific analysis. These models, while capable of comprehending the overall content of an image, struggle with more nuanced responsibilities like detailed region classification, specific object captioning, or profound reasoning based on specific image areas. This inadequacy underscores the pressing need for advanced models capable of dissecting and understanding images at an unprecedented level of granularity.
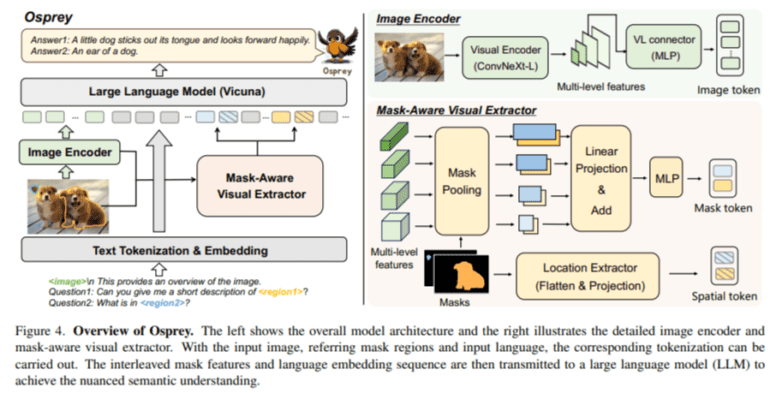
Enter Osprey, a groundbreaking solution developed collaboratively by researchers from Zhejiang University, Ant Group, Microsoft, and The Hong Kong Polytechnic University. Osprey introduces an innovative approach designed to elevate MLLMs by incorporating pixel-level instruction tuning to confront this challenge head-on. This method strives to achieve nothing short of a pixel-wise visual understanding, setting a new benchmark in the world of AI.
At the heart of Osprey lies the convolutional CLIP backbone, serving as its vision encoder, coupled with a mask-aware visual extractor. This symbiotic pairing constitutes a pivotal innovation, empowering Osprey to capture and decipher visual mask features from high-resolution inputs with unparalleled accuracy. The mask-aware optical extractor possesses the unique ability to discern and dissect specific regions within an image with surgical precision, enabling the model to not only understand but also eloquently describe these regions in meticulous detail. This transformative feature positions Osprey as a frontrunner in tasks that demand fine-grained image analysis, such as intricate object description and high-resolution image interpretation.
Osprey’s performance and prowess extend across diverse domains. Its remarkable proficiency in open-vocabulary recognition, object classification, and detailed region description sets it apart. The model’s capacity to generate fine-grained semantic outputs based on class-agnostic masks showcases Osprey’s advanced acumen in the realm of detailed image analysis, surpassing the existing models’ ability to interpret and elucidate specific image regions with unrivaled precision and depth. Osprey is not just a model; it’s a testament to the relentless pursuit of excellence in the world of AI, heralding a new era in multimodal language models.

Source: Marktechpost Media Inc.
Conclusion:
Osprey’s innovative approach to achieving fine-grained vision-language alignment in MLLMs represents a significant leap in AI capabilities. This advancement opens doors to a multitude of applications, from medical imaging analysis to high-resolution image interpretation, and positions Osprey as a game-changer in the AI market, meeting the increasing demand for precise and detailed image understanding in various industries.