
TL;DR:
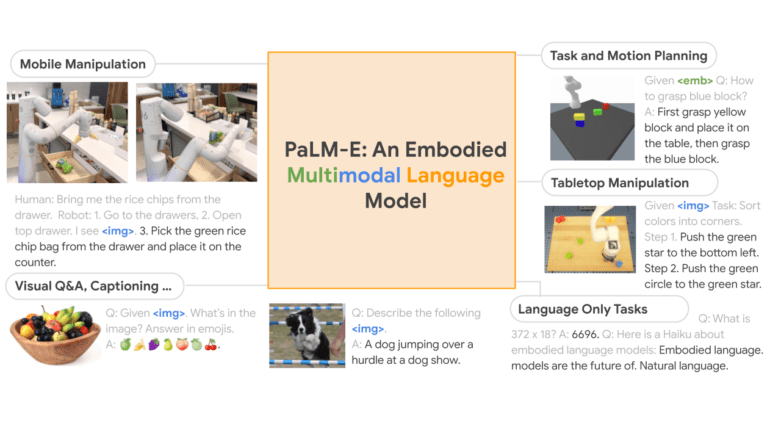
- PaLM-E is a groundbreaking 562-billion parameter embodied multimodal language model.
- It seamlessly connects textual data to real-world visual and physical sensor modalities, enhancing problem-solving in computer vision and robotics.
- Previous models were limited in their use of textual input alone, but PaLM-E’s continuous inputs enable more accurate decision-making.
- PaLM-E demonstrates positive transfer, excelling in a wide range of embodied reasoning problems across observation modalities.
- The model outperforms others in robotic manipulation, visual-language tasks, and language-related challenges.
- PaLM-E’s scale and capabilities make it the most extensive vision-language model ever published.
Main AI News:
In the fast-paced world of artificial intelligence, large language models (LLMs) are emerging as powerful tools, showcasing their impressive reasoning abilities in various fields. From holding engaging conversations to tackling complex math problems and even generating code, these LLMs have proven their versatility. However, a critical challenge lies in bridging the gap between textual data and real-world visual and physical sensor modalities, a key requirement for solving grounded problems in computer vision and robotics.
Previous efforts have sought to interface LLMs with learned robotic policies and affordance functions, but these approaches had their limitations. Primarily, they focused on textual input alone, overlooking the significance of the geometric configuration of the scene for many tasks. Researchers from Google and TU Berlin recognized this gap and endeavored to create a breakthrough solution – introducing embodied language models, which seamlessly integrate continuous inputs from an embodied agent’s sensor modalities. This innovative approach allows the language model, PaLM-E, to make more accurate conclusions and excel in sequential decision-making within the real world.
PaLM-E, a single, robust embodied multimodal model, has demonstrated positive transfer, a phenomenon akin to the fast and effective acquisition of a second language when a learner already possesses knowledge in a similar first language. The model’s ability to draw from this transfer learning enables it to solve a diverse array of embodied reasoning problems across different observation modalities and embodiments.
Functionally, PaLM-E processes language tokens and incorporates inputs like pictures and state estimations within the same latent embedding using self-attention layers similar to Transformer-based LLMs. The continuous inputs are introduced via an encoder into a pre-trained LLM, which allows the embodied agent to comprehend the instructions in natural language and respond accordingly. Through rigorous testing, comparing various input representations and exploring co-training on multiple tasks, researchers have validated the effectiveness of PaLM-E in diverse contexts.
The results are remarkable. In three robotic manipulation domains, including two closed-loop scenarios in the real world, PaLM-E showcases unparalleled performance. Additionally, in common visual-language tasks such as visual question answering (VQA) and picture captioning, PaLM-E outperforms other models without the need for task-specific finetuning. Moreover, this powerful language model exhibits a wide range of skills, demonstrating its ability to excel in tasks like zero-shot multimodal chain-of-thought (CoT) few-shot prompting, OCR-free arithmetic reasoning, and multi-image reasoning.
The sheer scale of PaLM-E is awe-inspiring, with a staggering 562 billion parameters, making it the most extensive vision-language model ever published. By combining the strengths of the 540B PaLM LLM and the 22B Vision Transformer (ViT), researchers have unleashed a formidable force in the world of AI.
Conclusion:
The introduction of PaLM-E marks a significant advancement in the field of AI for robotics and computer vision. Its ability to bridge textual and sensory data enhances problem-solving capabilities, and its positive transfer empowers the model to excel in various real-world scenarios. With its unmatched performance and scale, PaLM-E is poised to disrupt the market and unlock new possibilities in AI applications for industries such as robotics, automation, and computer vision. Businesses should keep a close eye on the developments around PaLM-E, as it holds the potential to revolutionize the way AI systems interact with and comprehend the physical world, leading to increased efficiency, precision, and adaptability in a wide range of industries.