
TL;DR:
- Language modeling is crucial for tasks like machine translation and text summarization.
- ‘Feature collapse’ problem hampers model expressiveness and performance.
- PanGu-π introduces nonlinearity enhancements through series-based activation functions and augmented shortcuts.
- PanGu-π-1B offers a 10% speed improvement, while YunShan excels in the financial sector.
- PanGu-π proves adaptable and suitable for finance-related applications.
Main AI News:
In the realm of natural language processing, language modeling stands as a critical pillar supporting machine translation, text summarization, and more. The nucleus of this evolutionary journey lies in the development of Large Language Models (LLMs) capable of seamlessly processing and generating human-like text, revolutionizing our interaction with technology.
Yet, a formidable challenge looms large in the domain of language modeling, known as the ‘feature collapse’ problem. This predicament resides within the very architecture of the model, where its expressive capacity faces constraints, resulting in diminished text generation quality and diversity. Addressing this issue is paramount to enhancing the performance and efficiency of LLMs.
Traditionally, endeavors to elevate language models have often focused on expanding model sizes and dataset dimensions to boost performance. However, this pursuit has led to monumental computational costs, rendering practical applications a daunting task. Recent studies have ventured into the realm of model architecture enhancements, with particular emphasis on the multi-head self-attention and feed-forward network components of the revered Transformer model.
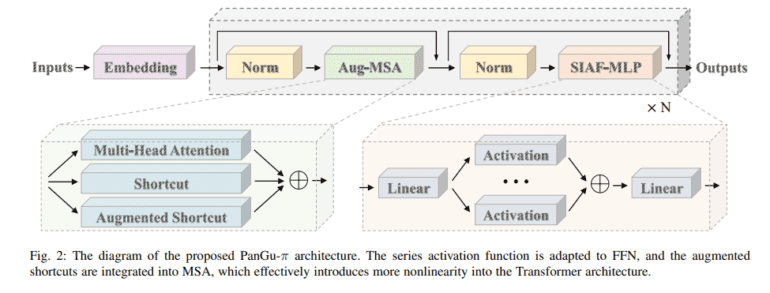
Enter the Huawei Noah’s Ark Lab research team, introducing a groundbreaking model architecture named PanGu-π. This architectural marvel sets its sights on mitigating the feature collapse problem by infusing the model with heightened nonlinearity. The innovation lies in the incorporation of series-based activation functions and augmented shortcuts within the Transformer framework. The result? PanGu-π exhibits an unprecedented level of nonlinearity, ushering in a new era for language models.
PanGu-π’s quest for nonlinearity encompasses two pivotal innovations. Firstly, it implements series-based activation functions within the Feed-Forward Network, infusing the model with increased complexity and expressiveness. Secondly, PanGu-π introduces augmented shortcuts in the Multi-Head Self-Attention modules, diversifying the model’s feature representation and enhancing its learning prowess.
This architectural masterpiece, PanGu-π, alongside its PanGu-π-1B variant, delivers a nonlinear and efficient design that boasts a remarkable 10% improvement in processing speed. Notably, the YunShan model, built upon the foundation of PanGu-π-7B, emerges as a champion in the financial sector, outshining its counterparts in specialized domains such as Economics and Banking. The FinEval benchmark illuminates PanGu-π’s prowess in Certificate and Accounting tasks, showcasing its exceptional adaptability and suitability for finance-related applications.
Conclusion:
The introduction of PanGu-π and its variants signifies a significant advancement in language models, enhancing both efficiency and performance. This innovation has the potential to reshape the market landscape, particularly in sectors like finance, where PanGu-π-7 B’s superiority promises substantial benefits for specialized applications.