
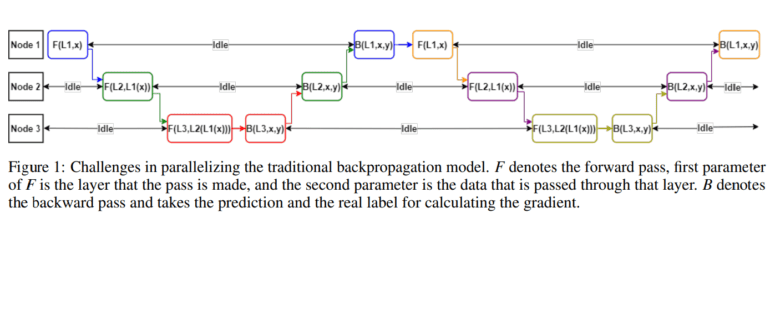
- Traditional backpropagation faces challenges in training deep neural networks in distributed systems.
- Recent frameworks like GPipe, PipeDream, and Flower optimize distributed deep learning, but still face communication overhead.
- Forward-Forward (FF) technique offers a local computation approach, reducing idle time and communication.
- Sabanci University introduces Pipeline Forward-Forward Algorithm (PFF), eliminating backpropagation dependencies.
- PFF achieves four times faster training with the same accuracy as FF and outperforms existing distributed implementations.
- Enhancements include parameter exchange, Federated Learning integration, multi-GPU architecture, and novel negative sample generation.
Main AI News:
When it comes to training deep neural networks, especially those with hundreds of layers, the conventional backpropagation method often leads to lengthy and cumbersome processes that can stretch over weeks. Despite its effectiveness on a single computing unit, the sequential nature of backpropagation poses challenges for parallelization in distributed systems. Each layer’s gradient computation relies on the gradient from the layer below, resulting in significant waiting times between nodes due to this sequential dependency. Moreover, frequent communication between nodes to exchange weight and gradient data adds to the overhead, particularly in large-scale neural networks where massive data transmission is required.
Addressing these challenges, recent years have seen a surge in distributed deep learning frameworks such as GPipe, PipeDream, and Flower. These frameworks leverage techniques like data, pipeline, and model parallelism to efficiently manage and train large-scale neural networks across distributed processing nodes, optimizing for speed, usability, cost, and size.
In the realm of distributed neural network training, a new approach emerges with the Forward-Forward (FF) technique pioneered by Hinton. Unlike traditional deep learning algorithms, FF conducts computations locally, layer by layer, offering a less dependent architecture that minimizes idle time, communication, and synchronization. Building upon FF, Sabanci University introduces the Pipeline Forward-Forward Algorithm (PFF), which eliminates the dependencies of backpropagation, resulting in higher utilization of computational units with reduced bubbles and idle time.
Experimental results demonstrate the efficacy of PFF, showing a fourfold increase in speed compared to typical FF implementations while maintaining the same level of accuracy. Moreover, compared to existing distributed Forward-Forward implementations (DFF), PFF achieves 5% higher accuracy in 10% fewer epochs, showcasing substantial benefits. This improvement is attributed to PFF’s transmission of only layer information, such as weights and biases, leading to lower communication overhead compared to DFF’s transmission of entire output data.
In addition to its performance advantages, the study suggests several enhancements for PFF:
- Exploring parameter exchange between layers after each batch to potentially improve accuracy, albeit with a risk of increased communication overhead.
- Utilizing PFF in Federated Learning setups, leveraging its data privacy-preserving properties.
- Considering a multi-GPU architecture to reduce communication overhead by physically grouping processing units together.
- Investigating novel methods for generating negative samples to enhance the learning process and overall system performance.
As the team behind PFF continues to refine and explore its potential, this research marks a significant milestone in the evolution of Distributed Neural Network training methodologies.
Conclusion:
The introduction of Pipeline Forward-Forward Algorithm (PFF) marks a significant advancement in distributed neural network training methodologies. By eliminating the dependencies of traditional backpropagation, PFF not only accelerates training processes but also reduces communication overhead. This innovation has the potential to reshape the market landscape, offering more efficient and scalable solutions for training large-scale neural networks in distributed environments. Businesses operating in the AI and deep learning sectors should closely monitor the development and adoption of PFF to stay competitive in this rapidly evolving landscape.