
TL;DR:
- PLATO, developed by Stanford University researchers, leverages knowledge graphs (KG) to address overfitting in high-dimensional, low-sample machine learning.
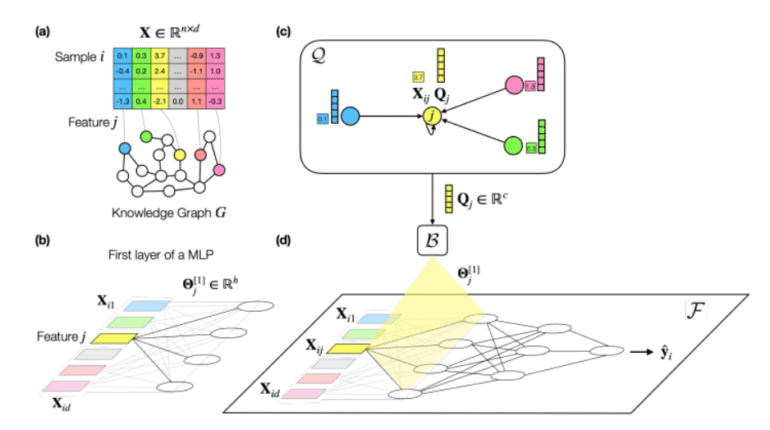
- It regularizes multilayer perceptrons (MLPs) by introducing an inductive bias, ensuring similar nodes in the KG have equivalent weight vectors in the MLP’s first layer.
- PLATO is designed for tabular datasets with high-dimensional features and limited samples, a niche often overlooked by existing methods.
- Unlike traditional approaches and deep tabular models, PLATO introduces KG-based regularization, including both feature and non-feature nodes, resulting in superior performance.
- PLATO associates input features with KG nodes, inferring weight vectors based on node similarity through multiple rounds of message passing.
- It outperforms 13 cutting-edge baselines by up to 10.19% across six datasets, confirming its effectiveness in the low-data regime.
Main AI News:
In the ever-evolving landscape of machine learning, the conundrum of overfitting has long plagued researchers and practitioners alike. However, a group of brilliant minds at Stanford University has unveiled a groundbreaking solution that promises to revolutionize the field. Introducing PLATO – an innovative AI approach that harnesses the power of knowledge graphs to tackle overfitting in high-dimensional, low-sample machine learning.
Understanding the Foundation: Knowledge Graphs and Multilayer Perceptrons
Before delving into the marvel that is PLATO, let’s grasp the fundamental components involved. A knowledge graph (KG) serves as a cornerstone, a graph-based database that stores information through nodes and edges. On the other hand, a multilayer perceptron (MLP) stands as a key player in machine learning, a neural network comprising interconnected nodes arranged in multiple layers. Each node in an MLP receives input from the preceding layer and transmits output to the subsequent layer.
PLATO Unveiled: The Game-Changer in Machine Learning
Stanford’s visionary researchers have introduced PLATO, a machine learning model that employs a KG to provide vital domain-specific information. At its core, PLATO takes on the role of a regularizer for MLPs, introducing an inductive bias that ensures that nodes within the KG possess equivalent weight vectors in the MLP’s initial layer. This groundbreaking approach addresses a longstanding challenge in machine learning – how to navigate tabular datasets laden with numerous dimensions compared to the number of available samples.
A Paradigm Shift in Tabular Data Handling
PLATO emerges as a trailblazer by addressing the relatively uncharted territory of tabular datasets featuring high-dimensional features and constrained sample sizes. It distinguishes itself from established deep tabular models like NODE and tabular transformers, as well as traditional methodologies such as PCA and LASSO, through the integration of a KG for regularization. What sets PLATO apart is its inclusion of both feature and non-feature nodes within the KG, enabling it to infer weights for an MLP model and employ the graph as a prior for predictions on diverse tabular datasets.
Elevating Performance in Data-Scarce Environments
Machine learning models have often thrived in data-rich settings but faltered when confronted with tabular datasets where the abundance of features far surpasses the number of samples. This predicament is particularly acute in scientific datasets, where it has limited model efficacy. Existing approaches to tabular deep learning primarily focus on scenarios with more examples than features, leaving the low-data regime with more features than samples largely unaddressed. Enter PLATO, a framework that leverages an auxiliary KG to regularize MLPs, facilitating deep learning for tabular data characterized by an abundance of features relative to samples. The result? Superior performance on datasets replete with high-dimensional features and limited samples.
The Power of KG Integration
PLATO’s brilliance lies in its utilization of an auxiliary KG, associating each input feature with a KG node and deducing weight vectors for the MLP’s first layer based on node similarity. This innovative approach employs multiple rounds of message passing to refine feature embeddings. In rigorous ablation studies, PLATO consistently demonstrates exceptional performance across various shallow node embedding methods within the KG, including TransE, DistMult, and ComplEx. This pioneering method holds the promise of ushering in substantial improvements for deep learning models in data-scarce tabular environments.
Proven Excellence: Outperforming the Competition
PLATO’s impact is undeniable, as it surges ahead of 13 cutting-edge baselines by up to an astonishing 10.19% across six datasets. A comprehensive performance evaluation involves an extensive random search, comprising 500 configurations per model, and reporting the mean and standard deviation of Pearson correlation between predicted and actual values. The results unequivocally affirm PLATO’s effectiveness, showcasing its ability to harness an auxiliary KG to achieve robust performance even in the challenging low-data regime. Comparative analyses against an array of diverse baselines further underscore PLATO’s superiority, solidifying its position as an indispensable tool for enhancing predictions in tabular datasets.
Conclusion:
PLATO represents a quantum leap in the realm of machine learning, offering a potent solution to the perennial problem of overfitting in high-dimensional, low-sample environments. Its integration of knowledge graphs, coupled with its exceptional performance, makes it a must-have asset for anyone navigating the intricate landscape of tabular data analysis. Stanford’s research team has truly raised the bar with PLATO, and the future of machine learning looks brighter than ever.