
TL;DR:
- Prismer is a visionary vision-language model that stands out with its multi-modal generation capabilities.
- It uses an ensemble of domain experts, offering a scalable and resource-efficient alternative to training enormous models on massive datasets.
- Large pre-trained models demand extensive data and computational resources, making Prismer’s efficiency a key advantage.
- Prismer excels in visual question answering, image captioning, and image classification tasks, rivaling state-of-the-art models.
- Its architecture combines visual encoders with autoregressive language decoders, achieving seamless cross-attention training.
- By using pre-trained experts, Prismer optimally captures semantics and information from input images.
- Incorporating a growing number of modality specialists enhances Prismer’s performance.
- The model remains steady even with corrupted experts, demonstrating resilience to unhelpful opinions.
Main AI News:
In the realm of vision-language models, Prismer stands tall as an exceptional innovation, redefining the paradigm of multi-modal generation capabilities. Unlike its predecessors, Prismer achieves its prowess without the need for training colossal models on enormous datasets. Instead, it leverages the collective knowledge of an ensemble of domain experts, presenting a scalable and resource-efficient alternative.
The power of large pre-trained models cannot be denied, as they exhibit exceptional generalization across diverse tasks. However, their hunger for vast amounts of training data and computational resources comes at a considerable cost. With hundreds of billions of trainable parameters, these models often require a yottaFLOP-scale computing budget in the language domain.
Navigating the complexities of visual language learning poses unique challenges. While encompassing language processing, it demands expertise in visual and multi-modal thinking. Prismer deftly addresses this by employing projected multi-modal signals, harnessing a wide array of pre-trained experts. Whether it’s visual question answering or picture captioning, Prismer emerges triumphant in diverse vision-language reasoning tasks. Just like a prism refracts light into its components, Prismer masterfully dissects general reasoning tasks into more manageable chunks.
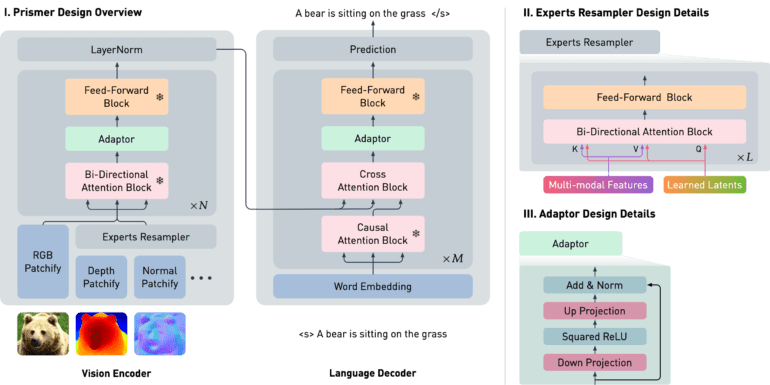
Key to Prismer’s architecture is two design features: (i) the utilization of language-only models and web-scale knowledge for constructing core network backbones, and (ii) modalities-specific vision experts encoding various visual information, ranging from low-level signals like depth to high-level ones like instance and semantic labels. This auxiliary knowledge is derived directly from their corresponding network outputs, enhancing the model’s reasoning capabilities.
A visually conditioned autoregressive text generation model has been developed, further optimizing the integration of various pre-trained domain experts for exploratory vision-language reasoning tasks.
Remarkably, Prismer’s training was based on a modest 13 million examples of publicly available image/alt-text data. Yet, it remarkably demonstrates robust multi-modal reasoning prowess in tasks such as image captioning, image classification, and visual question answering. Its performance competes head-to-head with state-of-the-art vision language models, a testament to its efficiency.
The Prismer model, built upon an encoder-decoder transformer version, draws strength from a vast pool of pre-trained subject matter experts, expediting the training process. Comprising a visual encoder and an autoregressive language decoder, this system operates seamlessly. The vision encoder takes in RGB and multi-modal labels, yielding corresponding features through cross-attention training. Consequently, the language decoder is skillfully conditioned to generate a string of text tokens.
The advantages of Prismer are manifold. It excels in utilizing data with utmost efficiency during its training, employing pre-trained vision-only and language-only backbone models to achieve comparable performance to other state-of-the-art vision-language models while significantly reducing GPU hours. Moreover, the creation of a multi-modal signal input for the vision encoder enhances the capture of semantics and information from input images. Prismer’s architecture optimally utilizes trained experts, with only a few trainable parameters, making it a model of remarkable efficiency.
Prismer features two types of pre-trained specialists: (1) “vision-only” and “language-only” models responsible for translating text and images into meaningful token sequences, and (2) Discourse Models with various labeling tasks, dependent on their training data.
The more modality specialists Prismer incorporates, the better its performance becomes. As the number of knowledgeable experts grows, so does the model’s prowess. Additionally, researchers have experimented with incorporating corrupted experts by introducing random noise from a Uniform Distribution, assessing the impact of expert quality on Prismer’s performance. The findings reveal that Prismer remains resilient and consistent even when noise-predicting experts are integrated.
Conclusion:
Prismer represents a groundbreaking advancement in the vision-language market. With its innovative ensemble approach and efficient utilization of pre-trained experts, it outshines traditional models, proving itself as a scalable, resource-saving, and high-performance solution. Businesses should keep a close eye on Prismer’s development, as it has the potential to disrupt the landscape and open up new possibilities for multi-modal generation and reasoning tasks. As this technology matures, organizations can leverage Prismer to boost their image captioning, visual question answering, and image classification capabilities, leading to improved user experiences and competitive advantages in the market.