
- Evaluating document instruction data for LLMs and MLLMs in document VQA is challenging with current text-focused methods.
- Existing approaches like InsTag and Instruction-Following Difficulty (IFD) have limitations in effectively assessing document instruction efficacy.
- ProcTag, developed by Alibaba Group and Zhejiang University, shifts focus from instruction text to the execution process, offering a more granular assessment.
- The method uses DocLayPrompt for document representation and GPT-3.5 for generating step-by-step pseudo-code, which is tagged for diversity and complexity.
- Experimental results show ProcTag significantly outperforms existing methods, achieving high efficacy with a fraction of the data.
- ProcTag’s approach improves training efficiency and model performance across diverse datasets.
Main AI News:
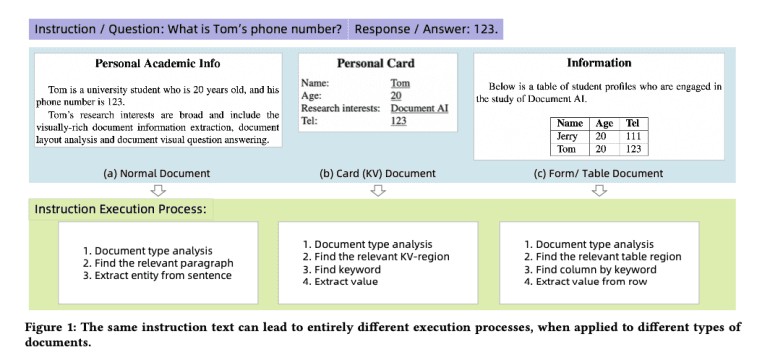
Evaluating document instruction data for training large language models (LLMs) and multimodal large language models (MLLMs) in document visual question answering (VQA) has long been a complex challenge. Traditional methods tend to be text-focused, prioritizing the textual content of instructions over the execution process itself. This approach limits their effectiveness in fully assessing the quality of instruction datasets, thereby impacting model performance in crucial tasks such as automated document analysis and information extraction.
Current methodologies like InsTag, while evaluating instruction text diversity and complexity, fall short in the document VQA domain due to varying execution processes required by different document types and layouts. Such limitations affect the selection and filtering of high-quality instruction data, leading to less effective model training outcomes. Additionally, techniques like Instruction-Following Difficulty (IFD) involve additional model training, which adds computational complexity and reduces practicality for real-time applications.
A novel solution comes from researchers at Alibaba Group and Zhejiang University with the introduction of ProcTag, a data-oriented approach that shifts the focus from instruction text to the execution process of document instructions. By tagging the execution process, ProcTag evaluates the efficacy of instruction datasets through the diversity and complexity of these tags. This method offers a more detailed assessment of data quality. Complementing this, the DocLayPrompt strategy enhances document representation by incorporating layout information, thereby improving LLM and MLLM training efficiency and performance in document VQA tasks.
ProcTag employs a structured approach to model the instruction execution process. It starts with representing documents using DocLayPrompt, which combines OCR and layout detection results to capture structural details. GPT-3.5 then generates step-by-step pseudo-code for instruction execution, which is tagged for diversity and complexity. These tags facilitate the filtering and selection of high-efficacy data. The method is applied to both manually annotated datasets like DocVQA and generated datasets such as RVL-CDIP and PublayNet. Key technical features include non-maximum suppression for data cleaning and clustering algorithms for tag aggregation.
Experimental results highlight ProcTag’s superior performance compared to existing methods like InsTag and random sampling. For instance, ProcTag-based sampling achieved full efficacy with only 30.5% of the DocVQA dataset, demonstrating its efficiency. Consistent improvements were observed across various data proportions and coverage rates during fine-tuning of LLMs and MLLMs, validating ProcTag’s effectiveness in enhancing model performance across diverse datasets.
Conclusion:
ProcTag’s introduction marks a significant advancement in the evaluation of document instruction data for AI training. By shifting the focus from textual content to the execution process, ProcTag offers a more accurate and detailed assessment of data quality. This innovation addresses key limitations of current methods, enhancing the training efficiency and performance of LLMs and MLLMs. For the market, ProcTag represents a pivotal development that could drive improved AI capabilities in document analysis and information extraction. Its robust performance across various datasets suggests that it may become a standard tool for optimizing instruction data evaluation and model training in the AI industry.