
TL;DR:
- ProPainter, a novel VI framework, pioneers dual-domain propagation for precise video inpainting.
- It introduces a mask-guided sparse video transformer to optimize computational efficiency.
- Outperforms predecessors with a 1.46 dB PSNR improvement, ensuring high-quality results.
- Addresses spatial misalignment and computational constraints, making it a valuable tool.
- Enhances video completion, object removal, and restoration tasks significantly.
Main AI News:
The realm of Artificial Intelligence continues its relentless evolution, with Computer Vision emerging as one of its pivotal subfields, garnering widespread attention. Within this domain, Video Inpainting (VI) stands as a remarkable technique, adept at seamlessly filling gaps and missing elements in videos. It accomplishes this while upholding both visual and temporal coherence, thus unlocking a world of applications ranging from video completeness to object, watermark, and logo removal. The overarching goal is to seamlessly integrate new content into the video, leaving no trace of the previously absent elements.
VI, however, poses formidable challenges due to its need for precise inter-frame correspondence for information integration. Earlier VI methods often undertook propagation in separate feature or image domains. Yet, this separation of global image propagation from the learning process could lead to spatial misalignments, primarily due to inaccurate optical flow estimations. Consequently, the inpainted regions might exhibit visual inconsistencies stemming from this misalignment.
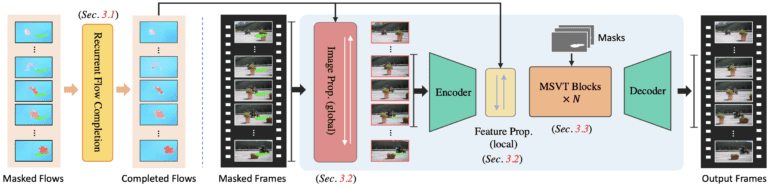
Another obstacle lies in the memory and computational constraints tied to feature propagation and video transformer techniques. These limitations impose a finite time window during which these strategies can be effectively deployed. Consequently, they fail to explore correspondence data from distant video frames, a crucial aspect of achieving flawless inpainting. In response, a team of researchers hailing from S-Lab at Nanyang Technological University introduces a groundbreaking VI framework: ProPainter.
ProPainter comprises two core components: Enhanced ProPagation and an Efficient Transformer. Notably, ProPainter pioneers the concept of dual-domain propagation, seeking to amalgamate the merits of feature-based and image-warping approaches. This innovative approach leverages the strengths of global correspondences while ensuring precise information dissemination. The result? Inpainting outcomes that exhibit heightened precision and visual uniformity, bridging the gap between image and feature-based propagation.
Augmenting its capabilities, ProPainter boasts a mask-guided sparse video transformer, complementing the dual-domain propagation. Unlike traditional spatiotemporal Transformers that demand substantial computational resources due to interactions among multiple video tokens, ProPainter adopts a different strategy. It directs its attention exclusively to relevant areas identified by inpainting masks. Given that inpainting masks typically cover specific video regions, with adjacent frames frequently displaying repeated textures, this approach eliminates redundant tokens, significantly reducing computational and memory burdens. This empowers the transformer to function optimally without compromising inpainting quality.
ProPainter eclipses its predecessors in the VI landscape, achieving an impressive 1.46 dB improvement in PSNR (Peak Signal-to-Noise Ratio), a benchmark statistic for image and video quality evaluation. In sum, ProPainter marks a pivotal milestone in the realm of video inpainting. It not only enhances performance but also addresses critical issues such as spatial misalignment and computational constraints, establishing itself as an invaluable tool for tasks like object removal, video completion, and video restoration.
Conclusion:
ProPainter’s innovative approach to video inpainting, combining dual-domain propagation and mask-guided efficiency, not only enhances the quality and precision of inpainting but also addresses critical industry challenges. This development represents a substantial leap forward in the market, making video completion, object removal, and restoration tasks more efficient and effective, ultimately driving innovation and competitiveness in the field of Computer Vision and AI.