
TL;DR:
- QMoE, a novel compression framework, solves the memory challenge of trillion-parameter Language Models (LMs).
- Mixture of Experts (MoE) architecture is powerful but resource-intensive.
- QMoE compresses 1.6 trillion parameters of Switch Transformer-c2048 to 160 GB, enabling efficient processing on a single GPU.
- It achieves sub-1-bit compression, making it an affordable reality with retraining-free techniques.
- QMoE employs intelligent component replication and data-dependent quantization methods.
- Popular frameworks like TensorFlow and PyTorch support quantization-aware training.
- Future work includes direct compression of pretrained base models and fine-tuning for specialized tasks.
Main AI News:
In the ever-evolving landscape of artificial intelligence, researchers are constantly pushing the boundaries of what is possible. Language models with trillions of parameters have become the new frontier, promising unparalleled capabilities but posing immense computational challenges. Enter QMoE, a groundbreaking compression framework that promises to revolutionize the way we harness the power of these massive models.
Mixture of Experts (MoE) architecture, a neural network model that combines the expertise of multiple subnetworks, has proven its mettle in handling complex and diverse data. Its ability to adapt and excel in various domains has made it a go-to choice for tackling challenging tasks. However, MoE models come at a cost, both in terms of computational resources and memory.
Consider the Switch Transformer-c2048 model, boasting a staggering 1.6 trillion parameters. Running this behemoth efficiently demands a whopping 3.2 terabytes of accelerator memory—an endeavor that has been both challenging and prohibitively expensive. Until now.
QMoE, the brainchild of researchers from ISTA Austria and Neural Magic, presents an elegant solution to this memory conundrum. This scalable algorithm achieves the remarkable feat of compressing trillion-parameter MoEs to less than 1 bit per parameter. In the case of the Switch Transformer-c2048 model, QMoE shrinks its 1.6 trillion parameters down to a manageable 160 gigabytes. What’s more, this can be processed in less than a day on a single GPU—a game-changer in the world of AI.
This achievement marks the first time accurate sub-1-bit compression of trillion-parameter MoEs has become not just a possibility but an affordable reality, thanks to retraining-free compression techniques.
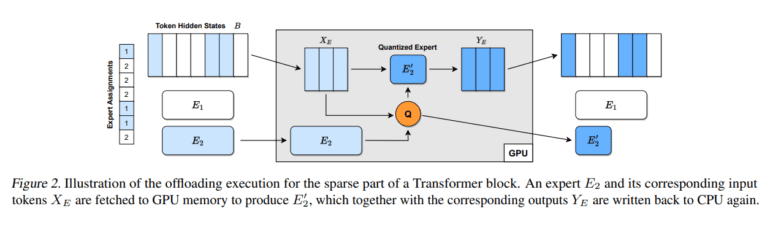
But how does QMoE work its magic? It’s all about intelligent component replication. QMoE creates copies of specific model components, each assigned to process a subset of input tokens. A router layer takes charge of these input-to-component assignments, ensuring efficient data flow. And the secret sauce? Quantization.
Quantization is the method du jour for reducing model size and weights to lower numerical precision. However, some MoEs are so massive that achieving practical compression rates requires more advanced data-dependent methods. Instead of training a neural network with full-precision (32-bit or 16-bit) weights and activations, data-dependent quantization methods train the model with quantized weights and activations. This allows the model to adapt to the constraints of lower-precision numerical representations.
Frameworks like TensorFlow, PyTorch, and TensorRT offer built-in support for quantization-aware training and calibration, making the implementation of QMoE a seamless process.
Looking ahead, the researchers have their sights set on further optimization. While they have focused on decoding operations and encoding matrices with commendable efficiency, the next frontier is the direct compression of the pretrained base model. Their future work will also encompass fine-tuning compressed models for specialized downstream tasks.
Conclusion:
QMoE’s breakthrough in efficient execution of trillion-parameter LMs is a game-changer for the AI market. It not only addresses the computational challenges but also makes these advanced models accessible and cost-effective. This innovation has the potential to drive widespread adoption of large-scale language models in various industries, from natural language understanding to content generation and beyond, fueling innovation and competitiveness in the AI market.