
TL;DR:
- Meta introduces RA-DIT, a two-stage fine-tuning methodology.
- RA-DIT enhances LLMs with efficient retrieval capabilities.
- It optimizes information utilization and retriever relevance.
- Outperforms existing models in knowledge-intensive tasks.
- Utilizes LLAMA model and parallel retrieval augmentation.
- RA-DIT 65B sets new benchmarks in zero/few-shot learning.
- Excels in contextual awareness and commonsense reasoning.
Main AI News:
In the realm of large language models (LLMs), the pursuit of effectively harnessing less common knowledge while mitigating the computational burdens of extensive pre-training has culminated in a groundbreaking innovation. Meta’s ingenious creation, Retrieval-Augmented Dual Instruction Tuning (RA-DIT), emerges as a beacon of hope. This innovative methodology is tailored to empower LLMs with streamlined retrieval capabilities, ushering in a new era of performance and versatility.
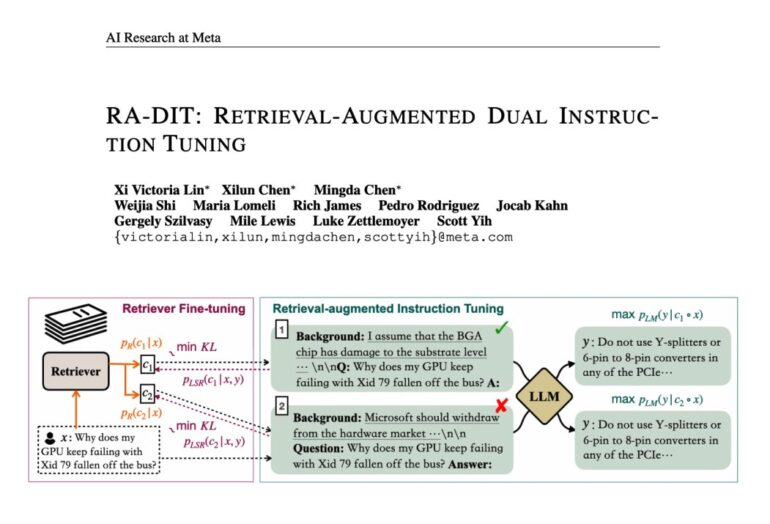
RA-DIT unfolds through a meticulous two-stage fine-tuning process, each delivering remarkable performance enhancements. The first stage optimizes the LLM’s adeptness in utilizing retrieved information, while the second refines the retriever, ensuring that it furnishes contextually pertinent results, precisely tailored to the LLM’s preferences. The result? RA-DIT emerges as a formidable solution, poised to elevate the capabilities of LLMs through seamless integration with retrieval mechanisms.
This two-stage fine-tuning methodology equips LLMs with the prowess to harness retrieved information optimally and augments retrievers to deliver results steeped in relevance. RA-DIT’s prowess becomes abundantly clear when it outperforms existing retrieval-augmented models in knowledge-intensive zero and few-shot learning benchmarks, thereby solidifying its dominance in the domain of infusing external knowledge into LLMs for unparalleled performance enhancement.
Meta’s vision for RA-DIT revolves around enhancing LLMs with retrieval capabilities. The journey consists of two pivotal fine-tuning stages. First, it optimizes a pre-trained LLM’s capacity to leverage retrieved information. Then, it meticulously hones the retriever to yield results that resonate seamlessly with the LLM’s contextual requirements. To achieve this feat, the researchers harness the LLAMA language model, which is pre-trained on an extensive dataset, and employ a dual-encoder-based retriever architecture, meticulously initialized with the formidable DRAGON model. In a quest for efficiency, parallel in-context retrieval augmentation is embraced, further streamlining the computational aspects of LLM predictions.
The outcome of their method is nothing short of extraordinary. RA-DIT 65B, the flagship model, blazes a trail by setting new standards in knowledge-intensive zero and few-shot learning tasks. It surpasses the existing in-context Retrieval-Augmented Language Models (RALMs) by a substantial margin, underlining the exceptional performance enhancements achieved by RA-DIT. This innovation stands as a testament to the transformative potential of lightweight instruction tuning, particularly in scenarios where access to vast external knowledge sources is paramount.
RA-DIT emerges as an unrivaled champion in knowledge-intensive zero and few-shot learning benchmarks. It outpaces existing in-context Retrieval-Augmented Language Models (RALMs) by a significant margin, achieving a remarkable +8.9% boost in the 0-shot setting and a commendable +1.4% improvement in the 5-shot location, on average. The zenith of this achievement is personified by RA-DIT 65B, showcasing substantial improvements in tasks necessitating knowledge utilization and contextual awareness. In the realm of parametric knowledge and reasoning capabilities, RA-DIT asserts its supremacy by outperforming base LLAMA models on 7 out of 8 commonsense reasoning evaluation datasets. Ablation analysis and parallel in-context retrieval augmentation serve as resounding endorsements of RA-DIT’s prowess in enhancing retrieval-augmented language models, especially when confronted with the demand for extensive knowledge access.
Conclusion:
RA-DIT represents a transformative breakthrough in the LLM landscape. It equips models with enhanced retrieval capabilities, offering superior performance in knowledge-intensive tasks. This innovation is poised to reshape the market, empowering businesses to leverage external knowledge more effectively for improved outcomes and competitiveness.