
TL;DR:
- Northwestern University, Tsinghua University, and the Chinese University of Hong Kong introduce ‘RAFA,’ a principled AI framework.
- RAFA enhances LLMs’ reasoning and action capabilities with verifiable regret guarantees.
- It employs a long-term trajectory planner for efficient decision-making.
- Utilizes Bayesian adaptive MDPs to represent reasoning in LLMs.
- RAFA excels in text-based benchmarks, including Game of 24, ALFWorld, BlocksWorld, and Tic-Tac-Toe.
Main AI News:
In the realm of cutting-edge Artificial Intelligence, the prowess of Language Model Machines (LLMs) is undeniable. However, their potential to effectively apply their remarkable reasoning capabilities in practical scenarios has long been a topic of exploration and refinement. The challenge lies in achieving tasks with utmost efficiency while minimizing interactions with the external world, a puzzle that has remained unsolved until now.
A groundbreaking study conducted jointly by Northwestern University, Tsinghua University, and the Chinese University of Hong Kong introduces a principled moral framework named “reason for future, act for now” (RAFA). This innovative framework not only offers a path to efficient execution but also delivers verifiable regret guarantees.
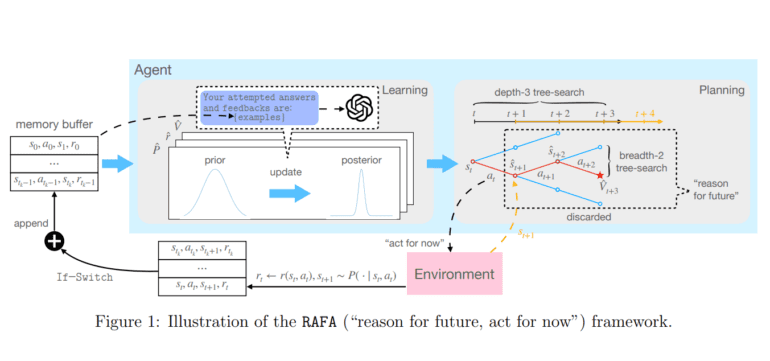
RAFA orchestrates the intricate dance between reasoning and action within the LLM domain. It involves the creation of a long-term trajectory planner known as “reason for future,” which learns from the memory buffer’s prompts for reasoning. This planner plays a pivotal role in ensuring that actions are meticulously charted and executed.
Within the framework of a Bayesian adaptive Markov Decision Process (MDP) paradigm, the study formally outlines the process of reasoning and acting with LLMs. At each juncture, the LLM agent takes its initial action based on the preplanned trajectory, aptly named “act for now.” Subsequently, it archives the acquired feedback in the memory buffer, triggering a fresh iteration of the reasoning routine to adapt its future trajectory according to the current state.
The core principle underpinning this approach is learning and planning within Bayesian adaptive Markov Decision Processes (MDPs). This principle is leveraged to model reasoning within LLMs as MDPs, thereby ensuring a systematic and rational approach to decision-making. The LLMs are further instructed to enhance their understanding of the unknown environment by consulting the memory buffer and devising a sequence of actions that optimizes a predefined value function. Should the external environment undergo a transformation, the LLM agent seamlessly engages its reasoning routine to recalibrate its course of action. To ensure the coherence of learning and planning, a switching condition is employed to determine the relevance of more recent historical data.
RAFA’s performance is rigorously assessed through a series of text-based benchmarks, including Game of 24, ALFWorld, BlocksWorld, and Tic-Tac-Toe. RAFA emerges as an AI powerhouse, utilizing linguistic models to excel in Reinforcement Learning and Planning (RL/PL) tasks. Here are the key takeaways:
- In the challenging game of 24, RAFA demonstrates its prowess by skillfully manipulating four different natural numbers through addition and subtraction to reach the coveted 24. Its remarkable sample efficiency sets it apart from the competition.
- ALFWorld, a virtual realm for household chore simulations, bears witness to RAFA’s superior performance. It outshines competing frameworks like AdaPlanner, ReAct, and Reflexion, showcasing its adaptability and efficiency.
- BlocksWorld presents a formidable test as players construct structures from blocks. RAFA’s success rates significantly outperform other models, such as Vicuna, RAP, and CoT, reaffirming its dominance in complex tasks.
- In the timeless game of Tic-Tac-Toe, RAFA takes on the role of “O” against a language model playing as “X.” Surprisingly, the “O” penalty does not deter RAFA, as it competes with and even surpasses the language model in certain scenarios. The researchers speculate that varying the planning depth (B = 3 or B = 4) could further optimize sample efficiency.
Conclusion:
RAFA’s introduction signifies a significant leap in AI research, promising unparalleled efficiency in integrating LLMs into practical applications. This innovation has the potential to reshape the AI market by offering businesses a robust and principled framework for optimizing decision-making processes, ultimately enhancing overall operational efficiency and competitiveness.