
TL;DR:
- Large Language Models (LLMs) like ChatGPT excel in various language tasks, including machine translation (MT).
- A recent study investigates LLMs, particularly ChatGPT, across 204 languages, including low-resource ones.
- The study emphasizes the need for evaluating LLMs’ performance in underrepresented languages.
- While ChatGPT performs well for high-resource languages, it struggles with low-resource African languages.
- Factors like language resources and script play key roles in LLM effectiveness.
- The financial aspect of LLM usage is considered, with few-shot prompts incurring higher costs.
- The study aims to guide end users and researchers in choosing the right MT system for specific language needs.
Main AI News:
In the realm of language technology, Large Language Models (LLMs) have been making waves, showcasing their exceptional capabilities across various language tasks, including machine translation (MT). However, the question that looms large is their effectiveness in handling low-resource languages (LRLs).
A recent research paper, published on September 14, 2023, takes a deep dive into the translation prowess of LLMs, with a special focus on ChatGPT, across an extensive spectrum of 204 languages, encompassing both high- and low-resource linguistic domains. What sets this study apart is that it provides “the first experimental evidence for an expansive set of 204 languages.”
The study, spearheaded by the Carnegie Mellon University team comprising Nathaniel R. Robinson, Perez Ogayo, David R. Mortensen, and Graham Neubig, underscores the urgency of such an investigation. They emphasize that there exists a vast array of languages for which the performance of recent LLM-based MT systems has never been comprehensively evaluated. This knowledge gap poses a significant challenge for speakers of diverse languages who seek to harness LLMs for their linguistic needs.
Furthermore, the authors draw attention to the stark reality that “the majority of LRLs are largely neglected in language technologies,” with current MT systems either delivering subpar results or entirely omitting them. They note that while some commercial systems like Google Translate extend support to a handful of LRLs, many others are left unsupported.
A distinctive aspect of this study is its user-centric approach. By including an impressive total of 204 languages, including 168 LRLs, the researchers affirm their commitment to addressing the varied requirements of LRL communities that often find themselves marginalized in discussions on language technology. “We encompass more languages than any previous study…to cater to the needs of diverse LRL communities,” they explain.
To conduct their comprehensive research, the team leveraged data from FLORES-200, an evaluation benchmark, and harnessed the OpenAI API to translate their test set from English into the target languages. The evaluation of ChatGPT’s MT performance spanned the entire language set, with comparisons made against NLLB-MOE, the current state-of-the-art open-source MT model renowned for its broad language coverage. Additionally, the study conducted comparative evaluations with results from selected languages using Google Translate and GPT-4.
In their exploration of MT prompts, the researchers employed both zero- and five-shot approaches for ChatGPT MT. The evaluation metrics, namely spBLEU and chrF2++, provided a robust foundation for assessing the quality of the translations.
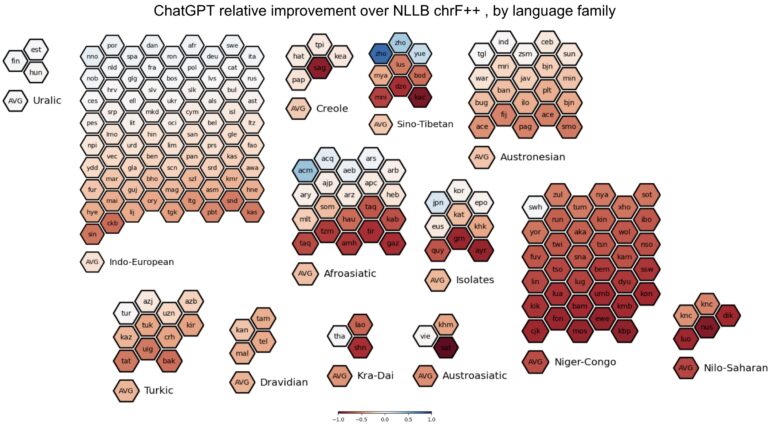
The findings reveal a complex landscape. While ChatGPT models approach or even exceed the performance of traditional MT models for certain high-resource languages, they consistently lag behind in the case of LRLs. Notably, African languages emerge as a formidable challenge, with ChatGPT underperforming traditional MT in a substantial 84.1% of the languages scrutinized.
In addition to performance, the study delves into language features, such as language resources, language family, and script, in an attempt to elucidate trends that can aid end users in selecting the most suitable MT system for their specific language needs. “Analyzing this may reveal trends helpful to end users deciding which MT system to use, especially if their language is not represented here but shares some of the features we consider,” they opine.
Among the factors considered, the study highlights a language’s resource level as the most crucial feature in predicting ChatGPT’s MT effectiveness, while script plays the least significant role.
The financial aspect also takes center stage, particularly in the context of LLM users. The authors diligently evaluate monetary costs, recognizing that this is a pertinent concern for LLM users. It’s worth noting that few-shot prompts, while holding promise for incremental improvements in translation quality, come at a higher cost due to charges associated with both input and output tokens.
Conclusion:
The authors are steadfast in their mission to empower end users from diverse language communities by providing insights into when and how to leverage LLM-based MT systems. They anticipate that their contributions will be valuable not only to direct end users seeking translation assistance but also to researchers working on LRL translation, who may consider ChatGPT to enhance specialized MT systems.