
TL;DR:
- LLMs reshape NLP with human-level NLU and NLG (OpenAI, 2023).
- NLP community addresses evaluation gaps with innovative tasks and datasets.
- Challenges persist: task formats limit assessment, benchmark integrity at risk, metrics for open-ended QA subjective.
- Automated evaluators, like GPT-4, attempt to lower human evaluation costs.
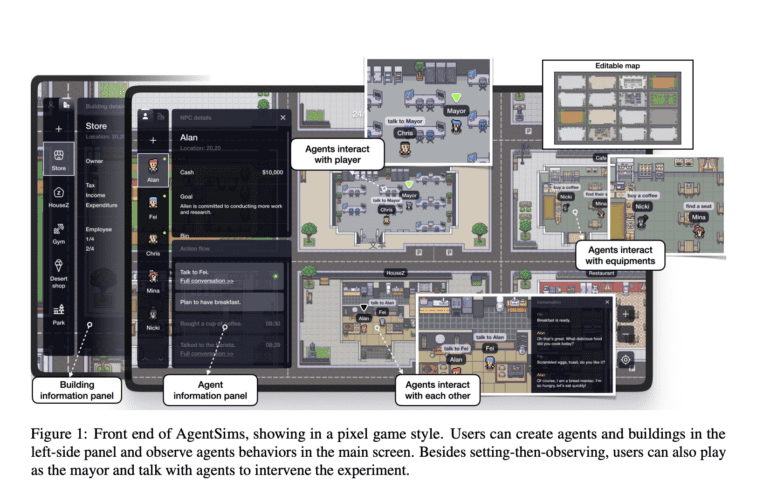
- AgentSims emerges as a solution, offering interactive evaluation tasks.
- AgentSims enhances task design, encourages interdisciplinary collaboration.
- Non-technical users empowered for dynamic task creation through user-friendly interfaces.
- AI professionals explore modifiable code for diverse LLM support systems.
- Goal-driven evaluation quantifies task success objectively.
- AgentSims fosters cross-disciplinary community development of robust LLM benchmarks.
Main AI News:
In the realm of natural language processing (NLP), the ascendancy of Large Language Models (LLMs) has redefined the landscape, yet the conundrum of their assessment endures. As LLMs seamlessly emulate Natural Language Understanding (NLU) and Natural Language Generation (NLG) at parity with human competence, a paradigm shift is discernible (OpenAI, 2023), propelled by the omnipresence of linguistic data.
To counter the exigent demand for novel yardsticks encompassing domains like closed-book question-answer (QA) knowledge assessment, human-centric standardized examinations, intricate multi-turn dialogues, cogent reasoning, and exhaustive safety scrutiny, the NLP community has orchestrated a symphony of inventive evaluation tasks and datasets that encompass a kaleidoscope of proficiencies.
However, persisting challenges continue to mar the efficacy of these modernized benchmarks:
- Formidable Constraints in Task Formats: Predominantly couched within single-turn QA paradigms, these evaluation activities inadvertently shackle the comprehensive breadth of LLM capacities, rendering them ill-equipped to fathom the multifaceted versatility LLMs wield.
- Vulnerability to Benchmark Manipulation: Ensuring the sanctity of test set integrity stands as a pivotal facet in gauging model efficacy. Regrettably, the unprecedented proliferation of LLM knowledge might surreptitiously taint test cases with pre-existing training data, casting a shadow of uncertainty.
- Subjectivity in Metrics for Open-ended QA: The lexicon of metrics for open-ended QA, erstwhile comprising objective and subjective human assessment, has been dethroned by the LLM epoch. Measures hinging on textual congruence have lost their relevance, paving the way for a fresh paradigm.
In response to these exigencies, the scholarly vanguard has turned to automated evaluators empowered by well-aligned LLMs, exemplified by the prowess of GPT-4. This stratagem endeavors to mitigate the substantial expense tied to human evaluations, albeit with an Achilles’ heel—its inability to grapple with supra-GPT-4 echelons of models.
Recent pioneering investigations led by luminaries from PTA Studio, Pennsylvania State University, Beihang University, Sun Yat-sen University, Zhejiang University, and East China Normal University introduce us to AgentSims—an avant-garde architectural marvel tailor-made for curating LLM evaluation tasks. Adorned with an interactive interface that captivates the senses and is fortified by a programmatic backbone, AgentSims emerges as a conduit for dismantling the obstacles encountered by researchers straddling a spectrum of programming prowess.
The cardinal ambition propelling AgentSims is to expedite the labyrinthine choreography of task design, assuaging the predicaments besetting researchers of disparate coding fluency. This felicitous design espouses extensibility and synergistic amalgamation, catalyzing investigations into hybridized strategies merging manifold blueprints, mnemonic constructs, and erudition systems.
AgentSims unfurls a red carpet, inviting savants from diverse domains encompassing behavioral economics to social psychology. Its intuitive cartography generation and stewardship of digital agents paves an accessible avenue, birthing a renaissance in interdisciplinary collaboration—indispensable for the evolutionary trajectory of the LLM domain.
The treatise articulates that AgentSims eclips prevailing LLM yardsticks, which often gauge a limited spectrum of competencies while grappling with nebulous criteria and data. Even non-technical luminaries in the social sciences find themselves empowered to engineer dynamic milieus and blueprint tasks through the prism of user-friendly menus and drag-and-drop interfaces.
This symphony of possibilities extends further as AI virtuosos and developers delve into the modifiable echelons of code—teasing apart abstracted agents, orchestrating cognitive choreography, manipulating memory schemas, and crafting tools of algorithmic engagement. With the lodestar of goal-driven evaluation, the voyage culminates in quantifying task triumph with objectivity.
Conclusion:
The advent of AgentSims heralds a transformative era for the language model market. With its pioneering approach to evaluation and task design, it resolves long-standing challenges in assessing LLMs. This innovation is set to invigorate interdisciplinary collaboration, democratize benchmark creation, and elevate the quality of LLM assessments. As the market evolves, AgentSims emerges as a pivotal driver of progress, steering the NLP landscape toward unparalleled proficiency and reliability.