
- ServiceNow researchers propose using Retrieval-Augmented Generation (RAG) to refine structured outputs of Large Language Models (LLMs).
- RAG integration significantly reduces hallucinations in workflow generation, improving reliability and usefulness.
- The method enhances LLM’s adaptability to non-domain contexts, increasing system versatility.
- Pairing a compact retriever model with LLM, enabled by RAG, optimizes resource utilization without performance compromise.
Main AI News:
In the realm of modern business operations, the integration of Large Language Models (LLMs) has heralded a new era of efficiency and productivity. These models facilitate tasks involving structured outputs, ranging from translating natural language into code or SQL to orchestrating complex workflows with logical connections. However, a persistent challenge has been the propensity for such systems to generate false or nonsensical outputs, termed as hallucinations, thereby impeding their universal acceptance and practical utility.
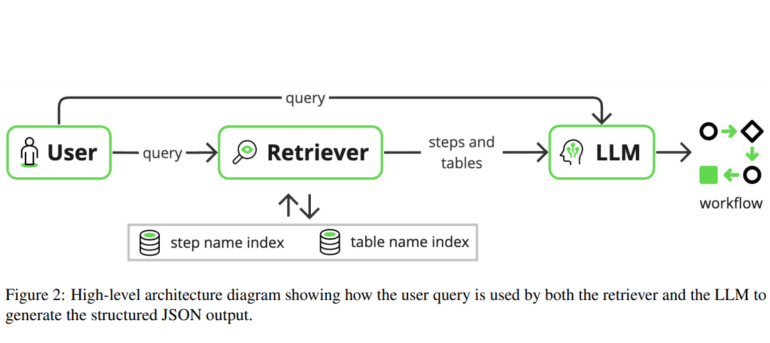
In a groundbreaking endeavor to mitigate this issue and enhance the adaptability of LLM-based systems, a pioneering team of researchers from ServiceNow has devised a sophisticated solution. Leveraging Retrieval-Augmented Generation (RAG), a cutting-edge method renowned for refining the quality of structured outputs, the team has developed an innovative system tailored for enterprise applications.
Through rigorous experimentation and implementation, the researchers demonstrated a remarkable reduction in hallucinations within workflow generation. By seamlessly integrating RAG into the workflow-generating framework, they bolstered the reliability and efficacy of the generated workflows, thereby addressing a critical bottleneck in the adoption of GenAI systems. Moreover, the system’s ability to generalize LLMs to diverse contexts amplifies its versatility and practicality across a spectrum of scenarios, irrespective of domain-specific constraints.
Furthermore, the team unveiled a pivotal finding regarding the optimization of model size without sacrificing performance. By pairing a compact retriever model with the LLM and harnessing the power of RAG, they achieved unprecedented efficiency gains. This optimization not only mitigates resource constraints but also streamlines deployment in real-world applications where computational resources are at a premium.
Conclusion:
The integration of Retrieval-Augmented Generation (RAG) marks a significant advancement in the efficiency and reliability of workflow generation systems powered by Large Language Models (LLMs). ServiceNow’s pioneering research not only mitigates the challenge of hallucinations but also enhances the adaptability and resource efficiency of such systems. This innovation holds immense promise for industries reliant on automated workflows, offering streamlined operations and improved productivity.