
- Researchers from Stanford and MIT introduce Stream of Search (SoS), enabling language models (LMs) to learn problem-solving through language exploration.
- SoS enhances LM training, addressing limitations in decision-making, planning, and reasoning.
- Pretraining LMs on SoS improves accuracy by 25%, with further fine-tuning leading to 36% success in solving previously unsolved problems.
- Recent studies integrate LMs into search and planning systems, emphasizing the need for improved reasoning abilities.
- SoS represents search processes as serialized strings, fostering autonomous self-improvement in LMs.
- Training LMs on suboptimal search trajectories outperforms training on optimal solutions for problem-solving tasks like Countdown.
- Self-improvement strategies such as reinforcement learning enhance LM proficiency in solving challenging problems.
Main AI News:
Researchers at prestigious institutions such as Stanford and MIT have recently introduced an innovative approach called the Stream of Search (SoS). This groundbreaking framework empowers language models (LMs) to enhance their problem-solving capabilities by delving into the language itself, devoid of any external support. LMs often face limitations during training, particularly in their ability to foresee consequences beyond immediate tokens. The imperative lies in augmenting their prowess in decision-making, planning, and reasoning, which are pivotal for their effectiveness in various applications.
Transformer-based models, despite their advancements, encounter hurdles in planning, primarily due to error accumulation and the intricacies involved in lookahead tasks. While some attempts have integrated symbolic search algorithms to mitigate these challenges, they typically serve as supplements during inference. However, the crux of the matter lies in enabling LMs to conduct searches during training, thereby fostering autonomous self-improvement and the development of adaptive strategies to tackle complex issues like error compounding and look-ahead tasks.
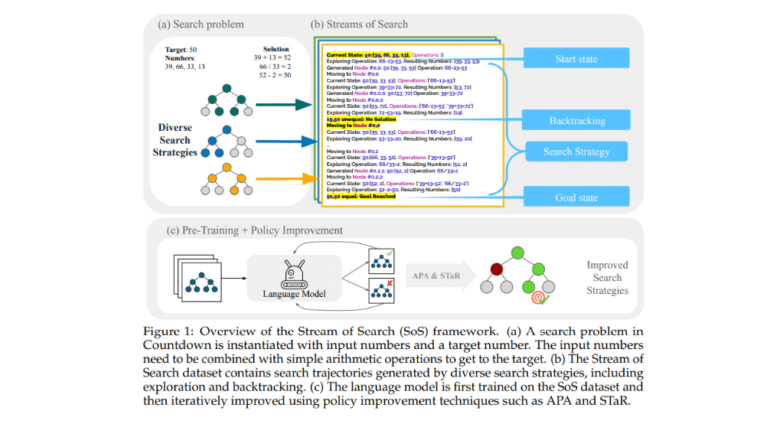
A team comprising researchers from Stanford University, MIT, and Harvey Mudd has devised a novel methodology to imbue language models with the ability to search and backtrack, encapsulated in the concept of SoS. This approach represents the search process as a serialized string, offering a unified language for search. To demonstrate its efficacy, the researchers applied this framework to the game of Countdown. Pretraining a transformer-based LM on streams of search resulted in a notable 25% increase in accuracy. Further fine-tuning, coupled with policy improvement methods, led to the successful resolution of 36% of previously unsolved problems. These findings underscore the potential of enabling LMs to learn problem-solving via search mechanisms, paving the way for autonomous discovery and self-improvement.
In recent studies, language models have been integrated into search and planning systems, tasked with generating and evaluating potential actions or states. While symbolic search algorithms like BFS or DFS are commonly employed for exploration strategy, LMs primarily serve inference purposes, necessitating advancements in reasoning ability. Conversely, in-context demonstrations leverage language to illustrate search procedures, enabling LMs to conduct tree searches accordingly. However, these methods are constrained by the demonstrated procedures. Process supervision entails training an external verifier model to offer detailed feedback for LM training, surpassing outcome supervision but demanding extensive labeled data.
The problem domain is delineated as a Markov Decision Process (MDP), encompassing states, actions, transitions, and reward functions that define the search process. The search entails traversing a tree from the initial to the goal state through sequences of states and actions. A vocabulary of primitive operations guides various search algorithms, including current state, goal state, state queue, state expansion, exploration choice, pruning, backtracking, goal check, and heuristic. For tasks like “Countdown,” a synthetic dataset with diverse search strategies is curated, assessing accuracy based on the model’s capability to generate correct solution trajectories and evaluating alignment between different search strategies through correctness and state overlap metrics.
Researchers delve into the effectiveness of training LMs on optimal solutions or suboptimal search trajectories for tackling Countdown problems. Utilizing a GPT-Neo model, they train on datasets representing both scenarios. Results indicate that models trained on suboptimal search trajectories outperform those trained on optimal solutions. Furthermore, they explore self-improvement strategies employing reinforcement learning (RL), such as expert iteration and Advantage-Induced Policy Alignment (APA). These strategies augment the model’s proficiency in solving previously unsolved and challenging problems, showcasing enhanced efficiency and accuracy in navigating the search space. Additionally, insights into the models’ search strategies unveil the flexible utilization of diverse methods, potentially leading to heuristic discoveries.
Conclusion:
The introduction of the Stream of Search framework signifies a significant advancement in empowering language models to autonomously learn problem-solving skills. This not only enhances their accuracy but also opens avenues for their integration into various industries, where autonomous decision-making and problem-solving capabilities are paramount. Businesses can leverage these developments to streamline operations, improve efficiency, and drive innovation in diverse applications, ranging from natural language processing to decision support systems.