
TL;DR:
- EPFL and Meta AI introduce Chain-of-Abstraction (CoA) reasoning method.
- CoA fine-tunes LLMs with abstract placeholders for multi-step reasoning.
- CoA enables efficient utilization of external tools for more accurate responses.
- Promotes effective planning by interconnecting tool calls, improving reasoning strategies.
- Separates general reasoning from domain-specific knowledge for parallel processing.
- CoA achieves superior performance in mathematical reasoning and Wiki QA domains.
- Average accuracy increase of ∼7.5% for mathematical reasoning and 4.5% for Wiki QA.
- Faster inference speeds, outpacing previous augmentation methods.
- Market implications: CoA enhances LLMs’ ability to tackle complex multi-step reasoning tasks, potentially revolutionizing industries reliant on natural language understanding and decision-making.
Main AI News:
In the realm of cutting-edge language models, researchers from EPFL and Meta AI have introduced a groundbreaking approach known as Chain-of-Abstraction (CoA) reasoning. This innovative method aims to enhance the capabilities of Large Language Models (LLMs) by facilitating their efficient utilization of auxiliary tools for multi-step reasoning. While LLMs have made remarkable strides in understanding and executing instructions, they often grapple with the accuracy of recalling and generating world knowledge, resulting in inaccuracies in their responses.
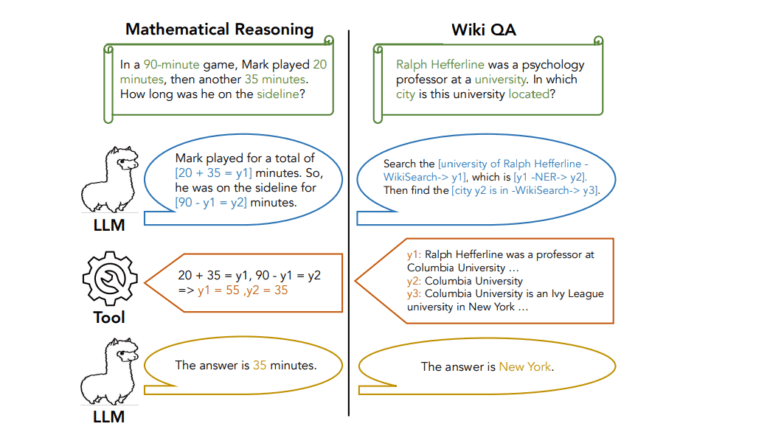
CoA reasoning addresses these challenges by introducing a robust and efficient strategy. The core concept of CoA reasoning involves fine-tuning LLMs to create reasoning chains that incorporate abstract placeholders, denoted as y1, y2, y3. These placeholders are subsequently substituted with specific knowledge acquired from external tools, such as calculators or web search engines, to ground the final answer generation process.
Unlike previous methods where LLM decoding and API calls were intertwined, CoA reasoning encourages effective planning by facilitating the interconnection of multiple tool calls and the adoption of more practical reasoning strategies. This abstract chain of reasoning enables LLMs to focus on general and holistic reasoning strategies without the need to generate instance-specific knowledge for the model’s parameters. Notably, this separation of general reasoning and domain-specific knowledge allows for parallel processing, where LLMs can generate the next abstract chain while tools fill the current one, thereby accelerating the overall inference process.
To train LLMs for CoA reasoning, the authors leverage existing open-source question-answering datasets and repurpose them to construct fine-tuning data. This entails re-writing answers as abstract chains, replacing specific operations with abstract placeholders. Subsequently, CoA traces are validated using domain-specialized tools to ensure precision and accuracy.
The CoA method undergoes rigorous evaluation in two distinct domains: mathematical reasoning and Wikipedia question answering (Wiki QA). In the realm of mathematical reasoning, LLMs trained on CoA data exhibit superior performance when compared to few-shot and regular fine-tuning baselines, excelling on both in-distribution and out-of-distribution datasets. Furthermore, CoA surpasses the Toolformer baseline in terms of effectiveness.
In the domain of Wiki QA, CoA is constructed using the HotpotQA dataset. Here, CoA outperforms various baselines, including Toolformer, showcasing remarkable generalization abilities across diverse question-answering datasets such as WebQuestions, NaturalQuestions, and TriviaQA. The inclusion of domain tools, such as a Wikipedia search engine and named-entity recognition toolkit, further bolsters CoA’s performance.
Overall, the evaluation results in both domains reveal substantial improvements with the CoA method, resulting in an average accuracy increase of approximately 7.5% for mathematical reasoning and 4.5% for Wiki QA. These enhancements extend to both in-distribution and out-of-distribution test sets, particularly benefiting questions that require intricate chain-of-thought reasoning. Additionally, CoA exhibits superior inference speeds, surpassing previous augmentation methods in mathematical reasoning and Wiki QA tasks. This research represents a significant leap forward in advancing the capabilities of Large Language Models in multi-step reasoning scenarios.
Conclusion:
The introduction of the Chain-of-Abstraction (CoA) reasoning method by EPFL and Meta AI signifies a major leap forward in improving the capabilities of Large Language Models (LLMs) for multi-step reasoning tasks. With its ability to enhance accuracy and efficiency, CoA is poised to have a positive impact on the market by improving the performance of LLM-dependent applications across various industries.