
TL;DR:
- Researchers from Microsoft, Peking University, and Xi’an Jiaotong University introduce LeMa, a novel technique to enhance large language models (LLMs).
- LeMa mimics human learning from mistakes to improve LLMs’ reasoning capabilities.
- LLMs often emulate surface-level reasoning without understanding underlying logic, resulting in errors.
- LeMa employs GPT-4 as a “corrector” to identify, explain, and rectify reasoning mistakes.
- Corrections are categorized as excellent, good, or poor, with 35 out of 50 achieving excellence.
- Corrected reasoning is fed back into LLMs to fine-tune and improve their performance.
- Testing on math reasoning tasks GSM8K and MATH shows significant improvement, with potential for specialized LLMs.
- GPT-3.5-Turbo is inadequate as a replacement for GPT-4 in the LeMa approach.
- GPT -4’s accuracy diminishes with increasing problem difficulty, indicating room for further improvement.
Main AI News:
In a collaborative effort between Microsoft, Peking University, and Xi’an Jiaotong University, researchers have unveiled an innovative technique that promises to enhance the reasoning abilities of large language models (LLMs). Their approach revolves around mimicking the way humans learn from their errors, providing a potential breakthrough in LLM-based problem-solving.
While LLMs have demonstrated their capacity to solve complex problems step-by-step, the critical facet of genuine reasoning has remained elusive. Often, these models tend to mimic the surface-level behaviors of human logic without truly grasping the underlying principles and rules required for precise reasoning. This limitation results in errors during the reasoning process, necessitating the intervention of a “world model” endowed with an inherent understanding of the logical and regulatory frameworks governing the real world.
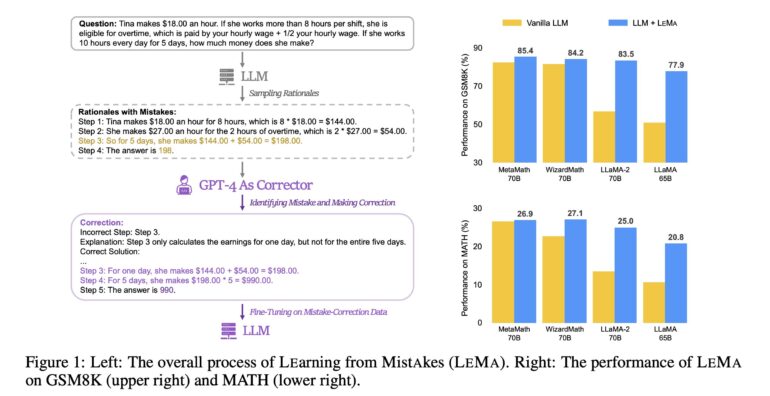
Enter “LeMa” (Learning from Mistakes), a novel approach that leverages GPT-4 as a corrective mechanism for rectifying inaccuracies in reasoning produced by various LLMs. For instance, consider a problem posed to LeMa: “James established a media empire, creating a movie for $2000. Each DVD costs $6 to manufacture, and he sells them at 2.5 times the production cost. Selling 500 movies a day for 5 days a week, what is his profit over 20 weeks?“
LeMa operates through a systematic three-step process. Initially, GPT-4 identifies the error in the reasoning. Subsequently, it offers an insightful explanation elucidating the root cause of the mistake. Finally, GPT-4 corrects the error, yielding a revised solution.
It is worth noting that LeMa’s performance varies across these steps, leading to the categorization of corrections into three groups based on their quality: excellent, good, or poor. Remarkably, the researchers discovered that 35 out of 50 generated corrections achieved excellence, with 11 rated as good and 4 deemed poor.
All correctly generated corrections are systematically fed back into the LLMs responsible for the initial answers, facilitating fine-tuning and refinement.
To evaluate the effectiveness of their approach, the research team conducted rigorous testing on two math reasoning tasks, GSM8K and MATH. The results were striking, demonstrating substantial improvements compared to previous methodologies. Furthermore, LeMa exhibited the potential to enhance the performance of specialized LLMs, such as WizardMath and MetaMath, achieving an impressive 85.4% pass@1 accuracy on GSM8K and 27.1% on MATH.
In a fascinating twist, the study also revealed that GPT-3.5-Turbo falls short in replacing GPT-4 as a corrector. Moreover, GPT -4’s accuracy witnessed a decline as problem difficulty increased, indicating a clear opportunity for further refinement and enhancement in this pioneering field of AI research.
Conclusion:
The LeMa approach represents a significant leap in enhancing the reasoning capabilities of large language models (LLMs). By emulating the way humans learn from their mistakes, LeMa addresses the limitations of LLMs in comprehending underlying logic and rules, substantially improving their performance on math reasoning tasks. This innovation not only augments LLMs’ problem-solving abilities but also has the potential to revolutionize various industries reliant on AI-driven reasoning, paving the way for more accurate and reliable AI applications.