
- Researchers from UCSD and USC introduced CyberDemo, an innovative AI framework for robotic imitation learning.
- Traditional methods of imitation learning in robotics face challenges due to the need for extensive human demonstration data.
- CyberDemo utilizes simulated human demonstrations to train robots for real-world manipulation tasks.
- The framework employs data augmentation techniques to enhance task performance and generate large datasets.
- CyberDemo outperforms traditional methods in various manipulation tasks, showing significant improvement in success rates.
- Evaluation against state-of-the-art vision pre-training models highlights CyberDemo’s efficiency and robustness.
Main AI News:
The realm of robotic manipulation has persistently posed formidable challenges within the spheres of automation and artificial intelligence, especially concerning tasks demanding intricate dexterity. Conventional imitation learning approaches, reliant on human demonstrations to impart complex task knowledge to robots, have grappled with the requirement for copious amounts of high-fidelity demonstration data. This prerequisite often translates into substantial human involvement, notably for tasks necessitating multifaceted dexterous manipulation.
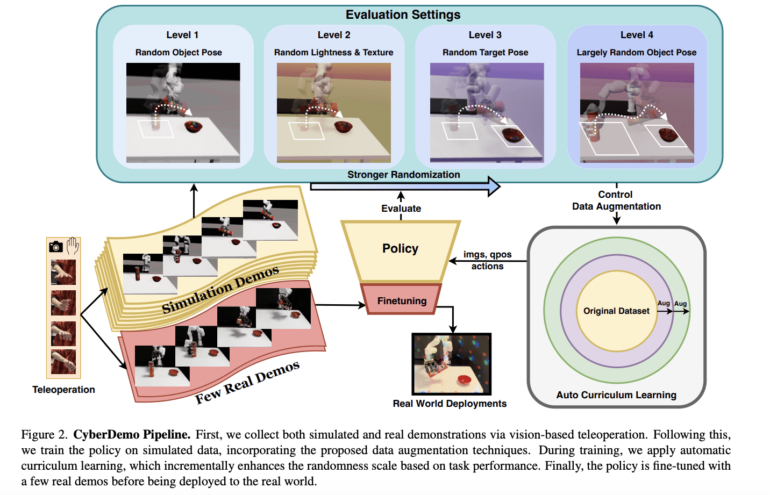
In response to these challenges, the present study introduces CyberDemo (Figure 2), an innovative framework leveraging simulated human demonstrations for real-world robotic manipulation endeavors. This paradigm not only alleviates the dependency on physical hardware, facilitating remote and parallel data acquisition, but also substantially enhances task efficacy through simulator-exclusive data augmentation methodologies (illustrated in Figure 3). By harnessing these techniques, CyberDemo can curate a dataset of unprecedented scale compared to what is feasible through real-world data collection alone. This functionality directly addresses a pivotal hurdle in the domain: the simulation-to-reality transfer, wherein policies trained in the simulation are effectively adapted for real-world implementation.
CyberDemo’s methodology commences with the acquisition of human demonstrations via teleoperation within a simulated environment employing economical devices. Subsequently, this data undergoes comprehensive augmentation to encompass a diverse spectrum of visual and physical scenarios not encountered during initial data capture. This procedural augmentation is designed to fortify the resilience of the trained policy against real-world variances. The framework adopts a curriculum learning approach for policy refinement, commencing with the augmented dataset and gradually integrating real-world demonstrations to fine-tune the policy. This methodological trajectory ensures a seamless simulation-to-reality transition, accommodating fluctuations in lighting conditions, object geometries, and initial poses sans the necessity for additional demonstrations.
The efficacy of CyberDemo is underscored by its performance (Figure 4) across an array of manipulation tasks. Relative to conventional methodologies, CyberDemo showcases a remarkable enhancement in task success rates. Specifically, CyberDemo achieves a success rate 35% higher for quasi-static tasks such as pick and place and 20% higher for non-quasi-static tasks like valve rotation compared to pre-trained policies fine-tuned solely on real-world demonstrations. Moreover, in assessments featuring unseen objects, CyberDemo’s capacity for generalization is particularly notable, demonstrating a success rate of 42.5% in rotating novel objects, a substantial advancement over conventional methodologies.
This methodology is evaluated against various benchmarks, including state-of-the-art vision pre-training models such as PVR, MVP, and R3M, traditionally utilized in robotic manipulation tasks. PVR, built upon MoCo-v2 with a ResNet50 backbone; MVP, utilizing self-supervised learning from a Masked Autoencoder with a Vision Transformer backbone; and R3M, amalgamating time-contrastive learning, video-language alignment, and L1 regularization with a ResNet50 backbone. The success of CyberDemo vis-à-vis these established models underscores its efficiency, resilience, and ability to surpass models fine-tuned exclusively on real-world demonstration datasets.
Conclusion:
The introduction of CyberDemo marks a significant advancement in the field of robotic imitation learning. By addressing the challenges posed by traditional methods and demonstrating superior performance in various tasks, CyberDemo has the potential to revolutionize the market for robotic automation and artificial intelligence. Its efficiency and robustness position it as a leading solution for businesses seeking to enhance their automation capabilities and improve task performance in diverse environments.