
TL;DR:
- Researchers introduce the sub-sentence encoder, a novel model for fine-grained semantic representation in text.
- This encoder generates distinct embeddings for atomic propositions within text sequences, offering unparalleled granularity.
- It excels in tasks such as retrieving supporting facts and recognizing conditional semantic similarity.
- The model maintains computational efficiency comparable to traditional sentence encoders, making it practical for various applications.
- Its potential applications extend to text evaluation, attribution, factuality estimation, and cross-document information linking.
- The sub-sentence encoder challenges the conventional approach of encoding entire text sequences into fixed-length vectors.
- Future research aims to explore multilingual applications and expand its scope beyond English text.
Main AI News:
In a groundbreaking collaboration, researchers hailing from esteemed institutions such as the University of Pennsylvania, the University of Washington, and Tencent AI Lab have unveiled a revolutionary development – the sub-sentence encoder. This innovative model has the power to reshape how we perceive and extract meaning from text.
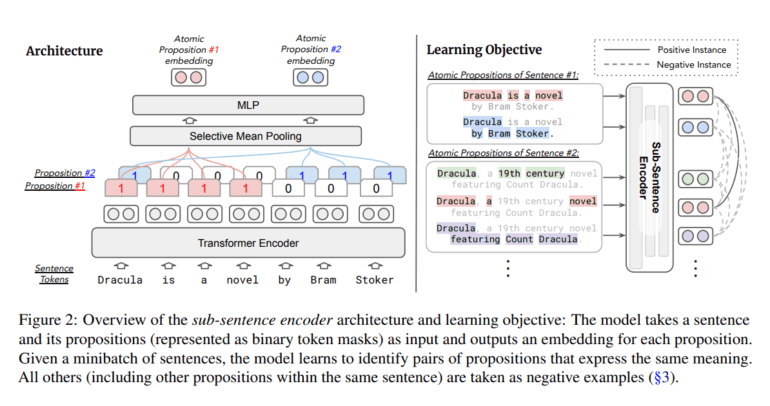
Unlike its conventional sentence-based counterparts, the sub-sentence encoder takes a deep dive into the intricacies of language. It excels in creating distinct embeddings for atomic propositions, the smallest units of meaning within a text sequence. The result? A fine-grained semantic representation that promises to elevate the way we interact with textual data.
One of its most impressive feats is the ability to retrieve supporting facts and identify conditional semantic similarities with unmatched precision. Remarkably, this level of sophistication doesn’t come at the expense of computational efficiency, as sub-sentence encoders maintain an inference cost and space complexity akin to traditional sentence encoders. This practicality opens doors to a multitude of applications in the world of business and beyond.
Imagine a tool that can pinpoint nuances in meaning within a text, making it invaluable for tasks like evaluating content, attributing sources, and estimating factual accuracy. The sub-sentence encoder, with its design tailored to address the needs of text attribution, stands poised to revolutionize cross-document information linking.
This research challenges the status quo of encoding entire text sequences into fixed-length vectors. Introducing the sub-sentence encoder paves the way for a new era of versatility in tasks demanding different levels of information granularity. The potential applications are boundless.
Furthermore, the study seeks to explore the utility of sub-sentence encoders across multiple languages, transcending the boundaries of English text. It introduces an automatic process for generating training data, making the adoption of this technology more accessible.
The results speak for themselves. The sub-sentence encoder outperforms traditional sentence encoders in discerning subtle semantic distinctions within the same context, delivering remarkable gains in precision and recall. It competes head-to-head with document-level and sentence-level models in atomic fact retrieval, showcasing its exceptional memory capabilities.
The sub-sentence encoder’s true strength lies in its adaptability across varying granularities. It offers a promising future for cross-document information linking and diverse retrieval tasks, serving as a potent tool for uncovering supporting propositions and enhancing recall for multi-vector retrieval.
This research marks a significant step forward in the realm of text evaluation, attribution, and factuality estimation. As it acknowledges the limitations in English text experiments, it sets the stage for future exploration into multilingual sub-sentence encoders and potential extensions into other languages. With a commitment to ongoing advancement, this work invites the world to delve deeper into the realm of sub-sentence encoder applications, igniting a new era of research possibilities in this domain.
Conclusion:
The introduction of the sub-sentence encoder signifies a major advancement in text understanding and processing. Its ability to provide fine-grained semantic representations and improve precision and recall has the potential to revolutionize various industries. Businesses can leverage this technology for more accurate content evaluation, better source attribution, and enhanced fact-checking processes. The model’s versatility in handling different levels of information granularity opens doors for innovative applications. As it transcends language barriers and aims for broader adoption, the sub-sentence encoder promises to play a significant role in shaping the future of text analytics and information retrieval across multiple markets.