
- Researchers from UC Santa Cruz, UC Davis, LuxiTech, and Soochow University have developed AI language models (LLMs) that operate without matrix multiplication (MatMul).
- Their MatMul-free approach utilizes ternary values and a custom MatMul-free Linear Gated Recurrent Unit (MLGRU) to streamline operations.
- The models achieve competitive performance comparable to traditional LLMs while significantly reducing memory usage and computational costs.
- Implemented on a custom FPGA chip, the models show promise for efficient deployment on hardware optimized for simpler arithmetic operations.
- Future scalability could potentially rival larger LLMs, addressing environmental concerns and operational costs associated with AI systems.
Main AI News:
In a significant breakthrough, researchers from the University of California Santa Cruz, UC Davis, LuxiTech, and Soochow University have unveiled a pioneering method to streamline AI language models (LLMs) by eliminating matrix multiplication from their computational processes. This innovation promises to fundamentally redesign neural network operations traditionally accelerated by GPU chips, potentially revolutionizing the environmental impact and operational costs associated with AI systems.
Matrix multiplication, often abbreviated as “MatMul,” serves as the cornerstone of most neural network computational tasks today. GPUs excel in executing these operations swiftly due to their ability to handle numerous multiplication tasks in parallel. This capability recently propelled Nvidia to the forefront as one of the world’s most valuable companies, commanding an estimated 98 percent market share for data center GPUs crucial for powering AI systems like ChatGPT and Google Gemini.
The researchers’ findings, detailed in their recent preprint paper titled “Scalable MatMul-free Language Modeling,” introduce a paradigm shift by presenting a custom-designed 2.7 billion parameter model that operates without relying on MatMul. Remarkably, this MatMul-free model demonstrates performance levels comparable to conventional large language models (LLMs), marking a significant stride towards more efficient AI hardware architectures.
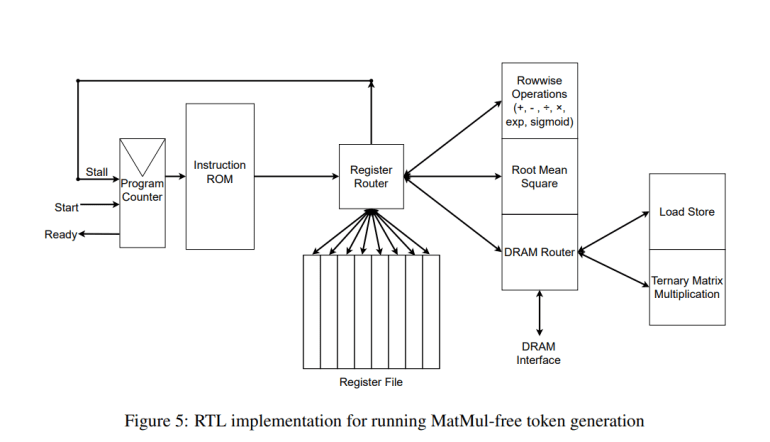
Central to their approach is the utilization of a custom-programmed FPGA (Field-Programmable Gate Array) chip, which accelerates model operations while consuming approximately 13 watts of power, excluding the GPU’s power draw. This FPGA implementation not only enhances computational efficiency but also underscores the feasibility of deploying AI models on hardware optimized for simpler arithmetic operations.
Lead researcher Rui-Jie Zhu explains, “While MatMul operations have long been considered indispensable for building high-performing language models, our research challenges this paradigm by demonstrating that MatMul-free architectures can achieve comparable performance.” Their innovative technique leverages ternary values (-1, 0, 1) instead of traditional floating-point numbers and introduces a MatMul-free Linear Gated Recurrent Unit (MLGRU) to streamline word processing within the model’s self-attention mechanism.
Furthermore, the researchers highlight significant reductions in memory usage facilitated by their optimized GPU implementation, slashing memory consumption by up to 61 percent during training compared to unoptimized baselines. Despite their current scale relative to market-leading LLMs such as GPT-4, which boasts over a trillion parameters, the researchers envision scalability potential that could rival larger models with increased computational resources.
Looking ahead, the team anticipates that their MatMul-free approach could surpass conventional LLM performance metrics at scales approaching 10²³ Floating Point Operations per Second (FLOPS), positioning it as a formidable contender in future AI advancements. However, they acknowledge the need for further investment in scaling up and refining their methodology to address the computational challenges of larger, more complex models.
For the AI community, this research represents a pivotal advancement towards achieving more accessible, sustainable, and efficient AI technologies. By reducing dependency on MatMul operations and optimizing hardware utilization, the researchers aim to reshape the landscape of language modeling and computational efficiency in AI systems.
Conclusion:
This groundbreaking research signifies a significant advancement in AI efficiency, potentially reshaping the market by reducing environmental impact and operational costs associated with AI systems. The ability to operate efficiently on hardware optimized for simpler arithmetic operations could democratize access to high-performance language models across various platforms, from smartphones to data centers.