
TL;DR:
- Language models (LLMs) are evolving into autonomous agents for task execution.
- Notable research showcases the effectiveness of LLM-based agents (e.g., React, Toolformer, HuggingGPT).
- The majority of current agents lack optimization due to LLM complexity.
- Reflection-based approaches (e.g., Reflexion, Self-Refine) utilize verbal feedback for learning.
- Retroformer, introduced by Salesforce Research, enhances language agents via a retrospective model.
- Retroformer refines pre-trained models iteratively using self-evaluation and credit allocation.
- Retroformer agents outperform in learning speed and decision-making (18% increase in HotPotQA success).
- Implication: Gradient-based planning and reasoning elevate tool usage in complex environments.
Main AI News:
A remarkable trend has surfaced, where expansive language models (LLMs) are evolving into self-reliant language agents, equipped not just to respond to user inquiries but to autonomously execute tasks, all in alignment with specific objectives. Renowned research undertakings such as React, Toolformer, HuggingGPT, generative agents, WebGPT, AutoGPT, BabyAGI, and Langchain have effectively showcased the feasibility of cultivating independent decision-making agents using LLMs. These methodologies harness LLMs to generate text-based outputs and actions that pave the way for API accessibility and task execution within distinct contexts.
However, a significant portion of existing language agents falls short in terms of optimized behaviors or congruence with environmental reward systems, owing to the extensive nature of LLMs characterized by their multitude of parameters. Reflexion, an emerging language agent architecture, and parallel works such as Self-Refine and Generative Agent deviate from this norm by incorporating verbal feedback, specifically through self-reflection, as a means to empower agents to learn from past setbacks. These reflective agents transform binary or scalar rewards from the environment into textual input—a summary that furnishes additional context to the agent’s initial prompt.
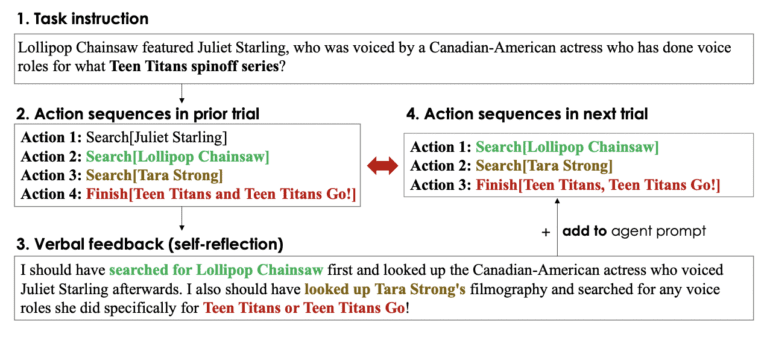
This form of self-reflective feedback operates as a semantic indicator, channeling the agent’s attention to precise areas necessitating improvement. Consequently, the agent assimilates lessons from previous missteps, minimizing the recurrence of errors and paving the way for better future performance. While the concept of iterative refinement thrives via self-reflection, generating insightful reflective feedback from a pre-trained and unalterable LLM can pose challenges, as illustrated in Figure 1. This stems from the necessity for the LLM to pinpoint the domains in which the agent faltered, such as the intricate credit assignment problem, and subsequently create a summary replete with recommendations for enhancement.
The frozen language model must undergo strategic adjustments to specialize in credit assignment concerns tailored to specific tasks and circumstances, optimizing the efficacy of verbal reinforcement. Furthermore, existing language agents often fall short in reasoning and strategizing in congruence with the differentiable, gradient-based learning methods utilized in today’s reinforcement learning landscape. Enter Retroformer, a visionary framework unveiled by researchers at Salesforce Research, is designed to fortify language agents through the acquisition of a plug-in retrospective model tailored for constraint-solving. Retroformer orchestrates enhancements to language agent prompts by ingesting input from the environment, all while adhering to policy optimization principles.
Notably, this agent architecture proposal facilitates the gradual refinement of a pre-trained language model, driven by a process of self-evaluation involving failed attempts and the judicious allocation of credits to actions with future rewards in sight. This dynamic unfolds by imbibing insights from diverse reward information stemming from a range of environments and tasks. Rigorous experimentation was conducted across open-source simulations and real-world scenarios, encompassing the HotPotQA framework—a landscape where web agents must iteratively engage with Wikipedia APIs to furnish answers. The HotPotQA milieu poses search-based question-answering challenges.
In stark contrast to non-gradient-oriented methods like reflection that fall short in contemplation and strategizing, Retroformer agents outshine as quick learners and adept decision-makers. To elaborate, Retroformer agents manifest an 18% surge in the HotPotQA success rate for search-based question-answering tasks within a mere four iterations, emphatically affirming the significance of gradient-based planning and reasoning in proficient tool utilization across environments characterized by intricate state-action dynamics.
Conclusion:
The emergence of Retroformer represents a significant leap in the evolution of language agents. By harnessing a plug-in retrospective model, this framework empowers agents to enhance their performance iteratively through self-reflection and strategic credit allocation. The success demonstrated in HotPotQA tasks and the superior learning speed of Retroformer agents underscores the potential for gradient-based planning and reasoning to reshape the landscape of AI tool usage in complex environments. This innovation holds substantial promise for the market, indicating a future where AI-powered language agents can rapidly adapt, learn, and excel in various demanding tasks.