
TL;DR:
- UC Berkeley introduces Anim-400K, a large-scale dataset for automated end-to-end video dubbing in Japanese and English.
- Global language distribution disparities compared to online content language are addressed.
- Dubbing and subtitling techniques are explored as solutions for linguistic accessibility in videos.
- Challenges in automated dubbing, despite advances in MT and ASR, include timing and prosody.
- The concept of end-to-end dubbing offers a breakthrough in capturing speaker nuances.
- Anim-400K dataset comprises over 425,000 aligned dubbed clips, setting new standards for scale and metadata support.
- Research covers data collection, dataset comparison, potential applications, and ethical considerations.
- Anim-400K empowers various video-related tasks and enhances research with enriched metadata.
Main AI News:
In an age of global connectivity, the linguistic chasm between the online content landscape and the diversity of global language speakers remains a glaring issue. While English dominates nearly 60% of the internet’s informational realm, it serves as the first language for only 5.1% of the world’s population, with a mere 18.8% being proficient speakers. For non-English speakers, this linguistic barrier presents a formidable challenge, especially when engaging with video content.
Eradicating Barriers through Dubbing
To bridge this gap, researchers have tirelessly explored the realms of subtitling and dubbing as two prominent techniques to make video content accessible to diverse linguistic audiences. Dubbing, the art of replacing original audio with native language tracks, and subtitles, translated to the target language, has emerged as a pivotal tools. Studies have demonstrated that dubbed videos, aimed at audiences who might be non-literate or early readers, can significantly enhance user engagement and retention.
The Technological Challenge
Despite significant strides in automated subtitling, driven by Machine Translation (MT) and Automatic Speech Recognition (ASR), automated dubbing remains a complex and costly process, often necessitating human intervention. Text-to-speech (TTS), ASR, and MT technologies are frequently amalgamated in intricate pipelines for automated dubbing systems. However, these systems grapple with nuances like timing, prosody, and facial expressions, which are indispensable for achieving top-tier dubbing quality.
The End-to-End Solution
Enter the concept of end-to-end dubbing, a groundbreaking approach that enables the generation of translated audio directly from raw source audio. This approach offers the remarkable ability to capture even the subtlest nuances of speaker performances, a vital ingredient for crafting high-quality dubbing.
UC Berkeley’s Game-Changing Contribution
In a recent research endeavor, a team of scholars from the University of California, Berkeley, unveiled the Anim-400K dataset, a game-changing resource comprising over 425,000 meticulously aligned dubbed clips. Anim-400K stands out for its synchronization capabilities, tailored to support multilingual operations like automated dubbing. It dwarfs existing collections of aligned dubbed videos in terms of scale and boasts robust metadata, facilitating a wide array of intricate video-related tasks.
The Comprehensive Study
The study encompasses several key aspects, including an in-depth examination of the data collection process, a comparative analysis of Anim-400K vis-à-vis other datasets, an elucidation of the potential applications enabled by Anim-400K, and a thought-provoking discussion on the dataset’s limitations and ethical considerations.
The Power of Anim-400K
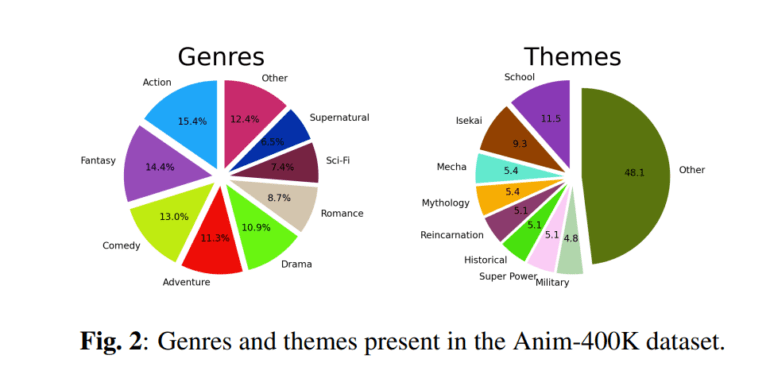
Anim-400K encompasses an extensive treasure trove of over 425,000 synchronized animated video segments available in both Japanese and English. This vast resource spans across 763 hours of music and video content from more than 190 properties, encompassing diverse themes and genres. Its utility extends to various video-related tasks, including guided video summarization, simultaneous translation, automatic dubbing, and genre, topic, and style classification.
Unleashing the Potential
To empower comprehensive research in the realm of audio-visual tasks, Anim-400K goes beyond the ordinary by enriching its dataset with metadata. This includes genres, themes, show ratings, character profiles, and animation styles at the property level, episode synopses, ratings, and subtitles at the episode level, and pre-computed ASR data at an aligned clip level. This wealth of information opens up new horizons for scholars and technologists alike, heralding a new era in the world of video dubbing and content accessibility.
Conclusion:
UC Berkeley’s Anim-400K dataset signifies a major leap forward in the field of video dubbing, offering a robust solution to linguistic disparities in online content. This resource has the potential to revolutionize the market by facilitating more efficient and high-quality automated dubbing processes, ultimately enhancing accessibility for diverse global audiences and expanding opportunities in the audio-visual industry.