
TL;DR:
- Large Language Models (LLMs) have proven their problem-solving ability across multiple domains.
- Memory bandwidth, not CPU power, is the primary performance limitation for LLM inference.
- Quantization, storing model parameters with reduced accuracy, offers a promising solution.
- UC Berkeley’s SqueezeLLM combines Dense-and-Sparse decomposition with non-uniform quantization to achieve ultra-low-bit precision quantization.
- SqueezeLLM significantly reduces model sizes and inference time costs while maintaining competitive performance.
- Extensive testing demonstrates SqueezeLLM’s superiority over existing quantization methods across various bit precisions.
- The framework addresses challenges like outliers in weight matrices and utilizes efficient sparse storage methods.
- SqueezeLLM outperforms state-of-the-art approaches in generating high-quality output while achieving remarkable latency reductions.
- The research contributes to advancements in quantization performance and inference efficiency for Large Language Models.
Main AI News:
The realm of Large Language Models (LLMs) has recently witnessed groundbreaking advancements, showcasing their remarkable problem-solving capabilities across various domains. With hundreds of billions of parameters and training on vast text corpora, LLMs have become powerhouses of knowledge and information processing.
Research indicates that memory bandwidth, rather than CPU power, poses the primary performance limitation for generative tasks in LLM inference. The ability to load and store parameters swiftly become the key latency barrier in memory-bound scenarios, overshadowing arithmetic operations. However, while computation has made significant strides, memory bandwidth technology has lagged behind, creating what is known as the Memory Wall.
Quantization emerges as a promising solution, involving the storage of model parameters with reduced accuracy compared to the standard 16 or 32 bits used during training. Despite recent developments like LLaMA and its instruction-following variations, achieving optimal quantization performance remains a challenge, particularly with lower bit precision and relatively modest models, such as those with 50 billion parameters.
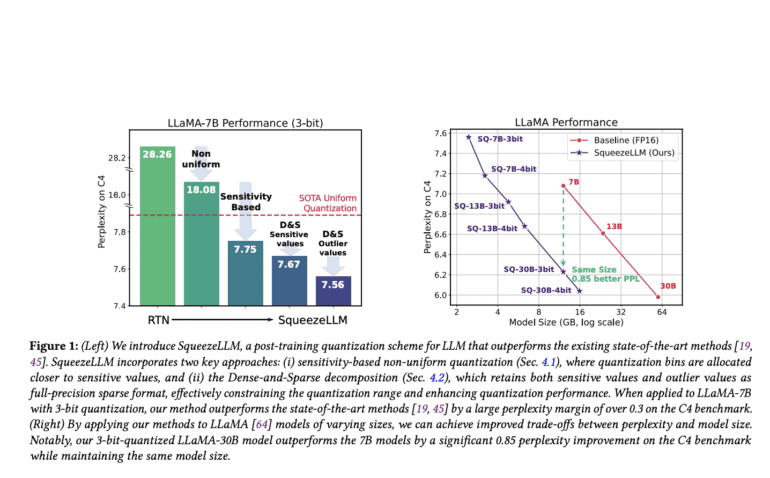
Addressing these challenges head-on, researchers at UC Berkeley have conducted an in-depth investigation into low-bit precision quantization, shedding light on the limitations of existing methodologies. Leveraging their findings, they introduce SqueezeLLM, a post-training quantization framework that combines Dense-and-Sparse decomposition with a unique sensitivity-based non-uniform quantization strategy. These innovative techniques enable ultra-low-bit precision quantization while maintaining competitive model performance, resulting in substantial reductions in model sizes and inference time costs. Notably, their approach significantly reduces the perplexity of the LLaMA-7B model from 28.26 to 7.75 on the C4 dataset when employing 3-bit precision with uniform quantization—an impressive improvement.
Extensive testing on the C4 and WikiText2 benchmarks has demonstrated the consistent superiority of SqueezeLLM over existing quantization methods across various bit precisions when applied to language modeling tasks using LLaMA-7B, 13B, and 30B models.
The research team highlights that achieving low-bit precision quantization in many LLMs is particularly challenging due to the presence of significant outliers in weight matrices. These outliers significantly impact non-uniform quantization, leading to the biased allocation of bits toward extremely high or low values. To overcome this obstacle, the researchers propose a straightforward method that separates the model weights into dense and sparse components, effectively isolating the extreme values.
This separation results in a narrower range within the central region, enhancing quantization precision. Efficient sparse storage techniques, such as Compressed Sparse Rows (CSR), allow the sparse data to be retained with full precision, minimizing overhead. By leveraging efficient sparse kernels for the sparse portion and parallelizing computation alongside the dense part, the proposed method achieves low latency with optimal utilization of resources.
The team further showcases the potential of their framework by quantizing IF models using SqueezeLLM on the Vicuna-7B and 13B models. The researchers conduct comparative tests using the MMLU dataset, a multi-task benchmark that measures a model’s knowledge and problem-solving abilities, to assess the quality of the generated output. They also employ GPT-4 to rank the generation quality of the quantized models in relation to the FP16 baseline, utilizing the evaluation methodology presented in Vicuna. In both benchmarks, SqueezeLLM consistently outperforms GPTQ and AWQ, two current state-of-the-art approaches. Notably, the 4-bit quantized model performs on par with the baseline in both assessments.
The groundbreaking work by UC Berkeley’s researchers showcases substantial reductions in latency and notable advancements in quantization performance when utilizing their models on A6000 GPUs. Speedups of up to 2.3 times compared to the baseline FP16 inference for LLaMA-7B and 13B models have been achieved. Additionally, the proposed method demonstrates up to 4 times faster latency than GPTQ, firmly establishing its efficacy in quantization performance and inference efficiency.
Conclusion:
UC Berkeley’s SqueezeLLM introduces a groundbreaking approach to enhancing the efficiency of Large Language Models through dense-and-sparse quantization. By addressing the challenges of low-bit precision quantization and leveraging innovative techniques, SqueezeLLM significantly reduces model sizes, inference time costs, and latency. This development has transformative implications for the market, as it opens up possibilities for deploying more efficient and high-performance AI systems in various industries. The combination of enhanced performance and reduced resource requirements positions SqueezeLLM as a valuable asset for organizations seeking to leverage the power of Large Language Models effectively.