
TL;DR:
- LLMs, such as MEDUSA, enhance language generation but face increased inference latency due to memory-bound operations during decoding.
- MEDUSA introduces multiple decoding heads for parallel token prediction, eliminating the need for a separate draft model.
- It reduces decoding steps, with minimal single-step latency, through efficient parallel processing and a tree-based attention mechanism.
- MEDUSA offers two fine-tuning methods: MEDUSA-1 for lossless inference acceleration with limited resources and MEDUSA-2 for superior speedup with abundant resources.
- Additional enhancements include acceptance schemes to elevate acceptance rates and self-distillation methods.
- Evaluation results demonstrate MEDUSA’s ability to accelerate data while maintaining generation quality.
Main AI News:
In today’s ever-evolving landscape of Artificial Intelligence (AI), Large Language Models (LLMs) have emerged as game-changers, pushing the boundaries of language generation. These behemoths, with their billion-parameter architectures, have infiltrated various sectors, from healthcare to finance and education, showcasing remarkable linguistic prowess.
However, as LLMs continue to grow in size and complexity, a conundrum surfaces—escalating inference latency. The culprit? Memory-bound operations that impede seamless auto-regressive decoding. Transporting copious model parameters from High Bandwidth Memory (HBM) to the accelerator’s cache proves inefficient.
To address this challenge, researchers are fervently exploring solutions. One promising approach involves reducing decoding steps while enhancing arithmetic intensity. Enter the concept of a smaller draft model for speculative decoding, generating initial tokens before refinement by the original model. Yet, integrating such a draft model into a distributed system presents its own set of obstacles.
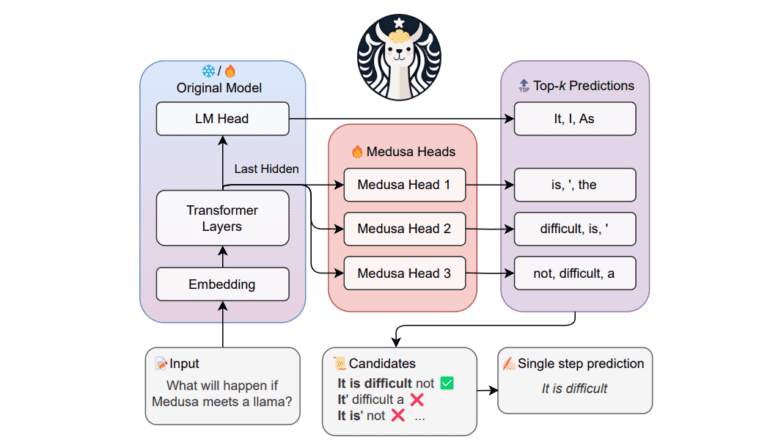
In response, a recent breakthrough emerges—MEDUSA, a groundbreaking framework designed to supercharge LLM inference. MEDUSA introduces multiple decoding heads to predict successive tokens in parallel, harnessing the power of the model’s decoding capabilities. This innovation conquers the hurdles of speculative decoding by concurrently predicting multiple tokens.
Remarkably, MEDUSA eliminates the need for a separate draft model, facilitating seamless integration into existing LLM systems, even in dispersed scenarios. This methodology constructs multiple candidate continuations during each decoding phase, scrutinizing them simultaneously through a tree-based attention mechanism. The result? A reduction in decoding steps with minimal single-step latency overhead, thanks to efficient parallel processing.
MEDUSA’s enhancements are twofold. Firstly, it generates numerous candidate continuations via its decoding heads, all validated in parallel. Secondly, it employs an acceptance procedure to select the most suitable candidates, drawing inspiration from the rejection sampling strategy in speculative decoding. A temperature-based threshold effectively handles any deviations, ensuring a refined output.
The study introduces two methods for fine-tuning LLMs with MEDUSA heads:
- MEDUSA-1: This method enables lossless inference acceleration by fine-tuning MEDUSA directly atop a frozen backbone LLM. Ideal for situations with limited computational resources, or when integrating MEDUSA into an existing model, it minimizes memory usage and can further optimize efficiency through quantization techniques.
- MEDUSA-2: While offering superior speedup and enhanced prediction accuracy for MEDUSA heads, this method concurrently adjusts MEDUSA and the main LLM. It requires a unique training recipe to preserve the backbone model’s functionality. MEDUSA-2 thrives in resource-abundant scenarios, allowing simultaneous training without compromising output quality or next-token prediction capability.
Additionally, the research suggests augmentations to bolster MEDUSA’s versatility, including an acceptance scheme to elevate acceptance rates without compromising generation quality and a self-distillation method in the absence of training data. Comprehensive evaluations across various model sizes and training protocols validate MEDUSA’s prowess. MEDUSA-1 accelerates data by over 2.2 times without sacrificing generation quality, while MEDUSA-2 pushes acceleration to an impressive 2.3-3.6 times.
Conclusion:
MEDUSA’s innovative approach to LLM inference addresses latency challenges and offers versatile fine-tuning options. This technology promises to revolutionize various markets by significantly improving the efficiency of language generation applications, opening doors to enhanced customer experiences, content creation, and data processing.