
TL;DR:
- CMU researchers introduce ReLM, an AI system for validating and querying LLMs using standard regular expressions.
- ReLM simplifies complex evaluation methods into regular expression queries, expanding statistical and prompt-tuning coverage up to 15 times compared to existing methods.
- It allows direct measurement of LLM behavior over vast collections without requiring in-depth knowledge of the LLM’s inner workings.
- ReLM adds a limited decoding system based on automaton theory to LLMs, enabling efficient and accurate execution of user-defined queries.
- The application of regular expressions to LLM forecasting is formally outlined, providing clear outcomes and surpassing the limitations of other question types.
- ReLM introduces conditional and unconditional classes of LLM inference queries, supporting compressed representations and accommodating variant encodings.
- A regular expression inference engine is implemented, converting regular expressions to finite automata with competitive GPU utilization and fast runtimes.
- ReLM’s value is exemplified through case studies using GPT-2 models, showcasing its effectiveness in addressing concerns of memorization, gender bias, toxicity, and language comprehension.
Main AI News:
Large language models (LLMs) have garnered immense praise for their ability to generate natural-sounding text. However, concerns have been raised regarding their potential negative impacts, such as data memorization, bias, and inappropriate language. Validating and rectifying these concerns is a challenging task due to the complexity and evolving capabilities of LLMs. In a groundbreaking study, researchers at CMU have unveiled ReLM (Regular Expression Language Model), a powerful system that addresses these challenges by employing standard regular expressions.
ReLM offers a formalized approach to evaluate and query LLMs, streamlining complex evaluation methods into regular expression queries. By utilizing ReLM, researchers can effectively address issues of memorization, gender prejudice, toxicity, and language comprehension. The results obtained from these inquiries demonstrate that ReLM significantly enhances statistical and prompt-tuning coverage by up to 15 times, surpassing the capabilities of existing ad hoc searches. As the demand for LLM validation continues to grow, ReLM serves as a competitive and versatile starting point for researchers in the field.
What sets ReLM apart is its ability to enable practitioners to directly measure LLM behavior across vast collections that are otherwise impossible to enumerate. By describing a query as the complete set of test patterns, ReLM empowers users to comprehensively assess LLM performance. This is achieved through a compact graph representation of the solution space, derived from regular expressions and compiled into an LLM-specific representation prior to execution. Users need not possess in-depth knowledge of the LLM’s inner workings, as ReLM produces results equivalent to the existence of all possible strings in the real world. In addition to introducing ReLM, the authors highlight the diverse applications of string patterns in various LLM evaluation tasks.
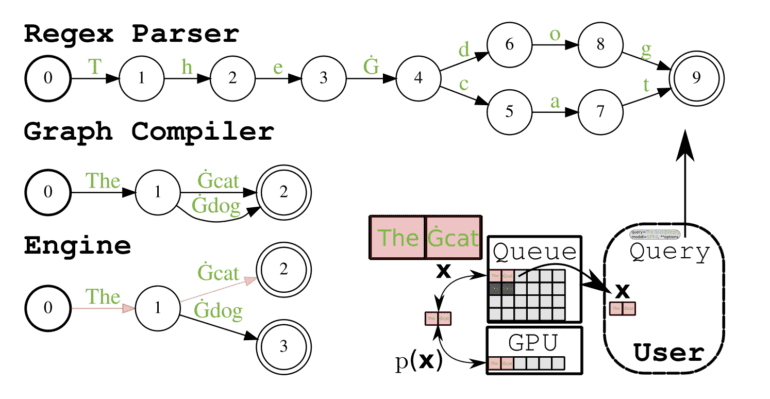
ReLM, short for Regular Expression engine for LMs, introduces a limited decoding system based on automaton theory to LLMs. Users can build queries within ReLM, incorporating test patterns and specifying the desired execution process. By allowing users to define the pattern of interest, ReLM avoids unnecessary effort, resulting in reduced false negatives. Furthermore, it encompasses often-ignored elements in the test set, minimizing false positives by considering variations of the pattern, such as encodings and misspellings. Through accurate propagation of effects to the final automaton, virtually any pattern or mutation can be described. ReLM provides Python user programs with a dedicated API, facilitating seamless integration and utilization of the framework alongside third-party libraries like Hugging Face Transformers.
Validation tasks using ReLM can be divided into two distinct stages. Firstly, users employ regular expressions to formally describe a subset of strings. Subsequently, they guide the engine through the process of string enumeration and evaluation. Researchers have demonstrated that ReLM executes common queries with remarkable speed and expressiveness, significantly reducing the validation effort required for LLMs. Notably, ReLM formalizes the application of regular expressions to LLM forecasting, enabling the description of sets of indefinite size. This surpasses the limitations of multiple-choice questions, which are restricted and enumerable. Compared to open-ended questions, ReLM consistently produces unambiguous outcomes.
The authors have also identified and constructed the conditional and unconditional classes of LLM inference queries. Given the flexibility of token sequences to represent a fixed query string, ReLM motivates the adoption of a compressed representation, as highlighted by academic studies on unconditional generation. This novel approach employs automata to accommodate variant encodings, making it the pioneering effort in this domain. Additionally, the researchers have designed and implemented a regular expression inference engine that effectively converts regular expressions into finite automata. Notably, this implementation demonstrates competitive GPU utilization and boasts impressive runtimes in mere seconds, thanks to both shortest path and randomized graph traversals.
To exemplify the value of ReLM in LLM validation, the authors present case studies utilizing GPT-2 models. These studies evaluate the performance of ReLM in the domains of memorization, gender bias, toxicity, and language comprehension tasks, further solidifying its significance in the field.
With ReLM, researchers and practitioners can embark on a new era of LLM validation and querying. Its innovative approach, leveraging regular expressions and automaton theory, enables comprehensive evaluation while addressing the potential pitfalls of large language models. As the complexities of LLMs continue to evolve, ReLM stands as a pioneering solution, empowering users to harness the full potential of these language models while ensuring their responsible and ethical usage.
Conclusion:
The introduction of ReLM revolutionizes the market for LLM validation and querying. Its streamlined approach using regular expressions enables comprehensive evaluation while simplifying the process for researchers and practitioners. ReLM’s ability to handle large-scale collections and offer a user-friendly interface reduces the validation effort required for LLMs, providing a competitive and generalized starting point for the industry. With ReLM, businesses can leverage the power of LLMs with enhanced confidence in their behavior, ensuring responsible and effective usage in various applications.