
TL;DR:
- Large Language Models (LLMs) are essential in AI applications.
- Current quantization methods for LLMs underutilize GPU capabilities.
- Researchers introduce Atom, a low-bit quantization technique.
- Atom enhances LLM serving throughput significantly without sacrificing precision.
- Achieves up to 7.73x improvement compared to 16-bit FP16 and 2.53x compared to 8-bit INT8 quantization.
- Atom’s contributions include fine-grained quantization, mixed precision, dynamic activation quantization, and KV-cache optimization.
- Proposes an integrated framework for long-term LLM servicing.
- Increases LLM efficiency without compromising accuracy.
Main AI News:
In the realm of artificial intelligence, large language models (LLMs) have emerged as game-changers, captivating the attention of researchers, scientists, and students alike. These remarkable models possess an uncanny ability to mimic human intelligence, adeptly tackling tasks such as question answering, content generation, text summarization, and code completion. As their popularity soars, the demand for LLMs across various domains, including sentiment analysis, intelligent chatbots, and content creation, continues to surge.
Yet, the computational prowess of LLMs comes at a cost, requiring substantial GPU resources to harness their full potential. LLM quantization techniques have been employed to optimize their efficiency and computational capacity. However, existing methods, such as 8-bit weight-activation quantization, fail to exploit the true capabilities of modern GPUs. With today’s GPUs boasting 4-bit integer operators, current quantization techniques are inherently suboptimal.
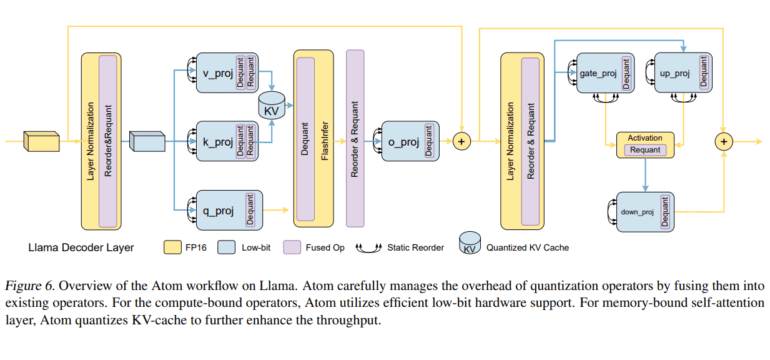
Enter Atom, a groundbreaking solution introduced by a dedicated team of researchers. Atom represents a paradigm shift in LLM quantization, designed to maximize serving throughput without compromising precision. Leveraging low-bit operators and quantization, this innovative approach significantly reduces memory usage. Atom achieves this by employing a unique blend of fine-grained and mixed-precision quantization techniques, ensuring exceptional accuracy.
The research team rigorously evaluated Atom, focusing on 4-bit weight-activation quantization configurations during serving. The results are nothing short of impressive. Atom maintains latency within the desired range while boosting end-to-end throughput by up to 7.73 times compared to the conventional 16-bit floating-point (FP16) approach and 2.53 times compared to 8-bit integer (INT8) quantization. This not only addresses the surging demand for LLM services but also enhances response times, turbocharging the speed at which LLMs process user requests.
The key contributions of this research can be summarized as follows:
- Thorough analysis of LLM serving, highlighting the substantial performance benefits derived from low-bit weight-activation quantization methods.
- Introduction of Atom, a precise low-bit weight-activation quantization technique that stands as a testament to innovation.
- Implementation of strategies within Atom to ensure peak performance, including mixed precision to maintain accuracy and fine-grained group quantization to minimize quantization errors.
- Incorporation of dynamic activation quantization in Atom, adapting to the unique input distribution and optimizing quantization accuracy. Additionally, Atom addresses the quantization of the KV-cache for improved overall performance.
- Proposal of an integrated framework for long-term management (LLM) servicing, featuring an effective inference system, low-bit GPU kernels, and a demonstration of Atom’s end-to-end throughput and latency in real-world scenarios.
- Comprehensive performance assessment revealing that Atom significantly enhances LLM serving throughput, achieving remarkable gains of up to 7.7 times while incurring only a negligible loss in accuracy.
Conclusion:
Atom’s introduction marks a significant advancement in the AI market. It promises to enable faster and more efficient Large Language Model services, meeting the increasing demand for AI applications while maintaining high precision. This innovation will likely drive adoption and competitiveness in the AI industry, making AI-powered solutions more accessible and responsive.