
TL;DR:
- Punica, developed by researchers at the University of Washington and Duke University, optimizes GPU resource utilization for LoRA models.
- LoRA (Low-Rank Adaptation) reduces trainable parameters in pre-trained language models for domain-specific tasks.
- Punica’s three design principles are GPU concentration, versatile batching, and decode stage optimization.
- Introduction of Segmented Gather Matrix-Vector Multiplication (SGMV) as a groundbreaking CUDA kernel.
- Punica’s efficient task arrangement strategies and minimal processing delay.
- Benchmark results show Punica achieves 12x greater throughput than competitors using the same GPU resources.
Main AI News:
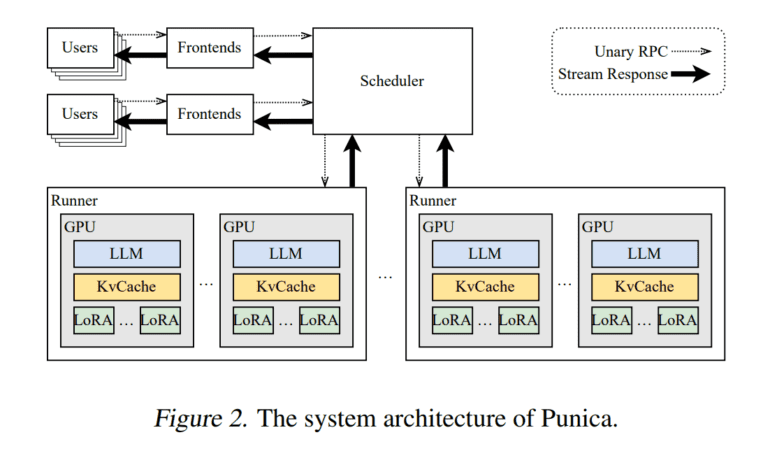
In the rapidly evolving landscape of artificial intelligence, the quest for optimal utilization of GPU resources in serving multiple LoRA models has become paramount. Researchers from the University of Washington and Duke University have unveiled a game-changing solution that promises to transform the way large language models (LLMs) are harnessed for domain-specific tasks. Meet Punica, the cutting-edge artificial intelligence system designed to cater to the needs of various LoRA models within a shared GPU cluster.
LoRA, or low-rank adaptation, has emerged as a favored approach for fine-tuning pre-trained LLMs to tackle specific tasks with minimal training data. By introducing trainable rank decomposition matrices to each layer of the Transformer architecture while preserving the pre-trained model’s weights, LoRA significantly reduces the number of trainable parameters. This innovation has opened doors to cost-effective domain specialization.
However, the conventional approach of treating each LoRA model as an independently trained entity often leads to inefficient GPU resource allocation. Punica’s creators recognize that weight correlations exist between LoRA models derived from the same pre-trained models, and they have identified three critical design principles to optimize the serving of multiple LoRA models.
Firstly, Punica acknowledges that GPUs are both expensive and in high demand. To maximize GPU usage, multi-tenant LoRA serving workloads are concentrated onto a limited number of GPUs, following the principle that fewer GPUs can achieve more with the right approach.
Secondly, Punica embraces the power of batching, a proven strategy to enhance performance and GPU utilization. Unlike traditional batch processing, which works efficiently for identical models, Punica extends batching to accommodate various LoRA models, ensuring seamless execution.
Lastly, Punica recognizes that the decode stage is where most model serving costs accrue. By focusing on optimizing this critical stage, Punica employs efficient methods like on-demand loading of LoRA model weights for less crucial components of model serving.
Punica’s core innovation lies in the introduction of Segmented Gather Matrix-Vector Multiplication (SGMV), a groundbreaking CUDA kernel. SGMV enables GPU operations to be batched for the concurrent execution of distinct LoRA models, dramatically enhancing GPU efficiency in terms of both memory and computation. Surprisingly, Punica’s research reveals minimal performance differences between batching the same LoRA models and batching different ones, showcasing its versatility.
Additionally, Punica minimizes the delay associated with the on-demand loading of LoRA model weights, ensuring that user requests are processed within milliseconds. This seamless and efficient approach allows Punica to consolidate user requests onto a smaller group of GPUs, optimizing resource allocation and utilization.
Punica’s task arrangement strategies are equally impressive. It directs fresh requests to a select group of GPUs already in use, maximizing their potential before committing further GPU resources. Regularly moving active requests for consolidation ensures the release of assigned GPU resources when they are no longer needed.
In a benchmark assessment using NVIDIA A100 GPU clusters, Punica demonstrated remarkable results, delivering an astonishing 12 times greater throughput than state-of-the-art LLM serving solutions with the same GPU resources. Punica’s ability to add only a 2ms delay per token while achieving such efficiency represents a paradigm shift in LoRA model serving.
Conclusion:
Punica stands as a testament to the relentless pursuit of efficiency and innovation in the field of multi-tenant AI serving. By adhering to the principles of GPU optimization, batching, and performance-driven design, Punica has set a new standard for LoRA model efficiency, revolutionizing the way AI resources are managed and utilized in a shared GPU cluster environment.