
- Recent advancements in Neural Machine Translation (NMT) address the disparity between high and low-resource languages.
- Meta’s Foundational AI Research (FAIR) introduces Sparsely Gated Mixture of Experts (MoE) models for enhanced translation.
- MoE models optimize translation accuracy by leveraging multiple experts and gating mechanisms.
- Expert Output Masking (EOM) emerges as a potent regularization strategy, surpassing traditional methods.
- Empirical results showcase a significant improvement in translation quality for low-resource languages, with notable gains in chrF++ scores.
- The MoE approach exhibits promise in diverse language pairs, indicating a potential breakthrough in global communication barriers.
Main AI News:
In the dynamic realm of Natural Language Processing (NLP), machine translation stands as a pivotal domain, tasked with the mission of bridging linguistic divides across the globe. Recent strides in Neural Machine Translation (NMT) have ushered in a new era of precision and fluidity, powered by the boundless potential of deep learning methodologies.
The persistent challenge, however, lies in the stark contrast between translation prowess among high-resource and low-resource languages. While the former luxuriates in abundant training data, enabling superior performance, the latter grapples with scant resources and consequent translation deficiencies. This chasm impedes seamless communication and equitable access to information, prompting an urgent call for innovative solutions.
Enter the pioneering research by Meta’s Foundational AI Research (FAIR) team, poised to revolutionize the landscape with Sparsely Gated Mixture of Experts (MoE) models. Embracing a multifaceted approach, this groundbreaking methodology harnesses the collective intelligence of diverse experts within the model architecture, thereby optimizing translation accuracy and circumventing interference across disparate language pairs.
Diverging from conventional dense transformers, MoE models introduce a paradigm shift, wherein select feed-forward network layers in the encoder and decoder are supplanted with MoE layers. Each MoE layer houses a cadre of experts, comprising individual feed-forward and gating networks, orchestrating a judicious allocation of input tokens. This structural innovation not only fosters cross-linguistic generalization but also enhances data utilization efficiency.
The methodological cornerstone of this endeavor lies in conditional computational modeling, wherein MoE layers, augmented with gating networks, are seamlessly integrated into the transformer encoder-decoder architecture. By optimizing a blend of label-smoothed cross-entropy and auxiliary load-balancing loss, the MoE model adeptly navigates the translation landscape, culminating in superior performance.
Central to this transformative journey is the concept of Expert Output Masking (EOM), a bespoke regularization strategy meticulously crafted to bolster model robustness. Outstripping traditional approaches like Gating Dropout, EOM emerges as a potent tool in the arsenal of translation enhancement.
The empirical validation of this paradigm shift underscores its efficacy, particularly in the realm of very low-resource languages. Witnessing a notable 12.5% surge in chrF++ scores for translations into English, the MoE models exemplify a quantum leap in translation fidelity. Furthermore, experiments conducted on the FLORES-200 development set, spanning diverse language pairs including Somali, Southern Sotho, Twi, Umbundu, and Venetian, unveil a promising trajectory. Following the filtration of parallel sentences by an average of 30%, translation quality registers a commendable 5% uptick, accompanied by a corresponding reduction in toxicity.
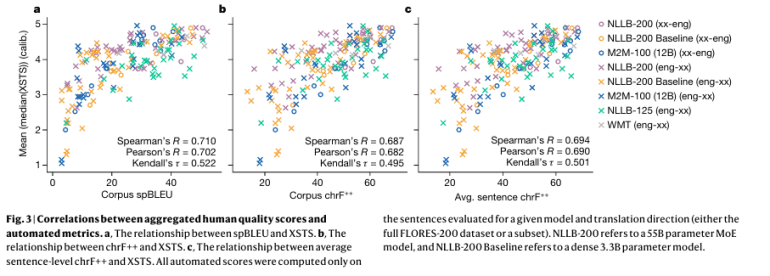
To corroborate these findings, a meticulous evaluation framework was instituted, amalgamating automated metrics with human quality assessments. Calibrated human evaluation scores emerged as a robust benchmark, mirroring the insights gleaned from automated counterparts and underscoring the efficacy of MoE models in reshaping the NMT landscape.
Conclusion:
The advent of Sparsely Gated MoE Models marks a pivotal moment in the NMT landscape, offering tangible solutions to address the longstanding challenges posed by linguistic disparities. This innovation not only enhances translation accuracy but also opens new avenues for seamless global communication, presenting lucrative opportunities for market players to capitalize on the evolving demands of multilingual societies.