
- Self-attention mechanisms in Transformers excel in capturing long-range dependencies but suffer from scalability issues due to quadratic complexity.
- Recurrent Neural Networks (RNNs) offer linear complexity but struggle with retaining information over lengthy sequences.
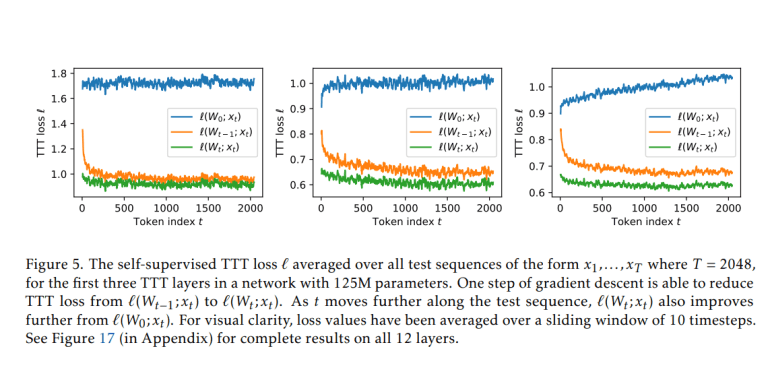
- Test-Time Training (TTT) layers integrate self-supervised learning into the hidden state update during both training and testing phases.
- TTT-Linear uses a linear model for its hidden state, matching RNN performance with reduced processing time.
- TTT-MLP employs a two-layer Multilayer Perceptron (MLP) for enhanced sequence prediction accuracy, albeit with higher memory demands.
- The introduction of mini-batch TTT and its dual form optimizes hardware efficiency, making TTT-Linear pivotal for scaling large language models.
Main AI News:
The team of researchers from Stanford University, UC San Diego, UC Berkeley, and Meta AI has pioneered Test-Time Training (TTT) layers, a groundbreaking approach in sequence modeling. Traditional methods face challenges with computational efficiency and memory constraints as sequence lengths grow. Self-attention mechanisms, as seen in Transformers, excel at capturing long-range dependencies but suffer from quadratic complexity, making them less scalable for very large sequences.
In contrast, Recurrent Neural Networks (RNNs) offer linear complexity but struggle with retaining information over lengthy contexts due to limitations in their hidden state architecture. To bridge these gaps, the research team has introduced TTT layers, which integrate a self-supervised learning mechanism into the model’s hidden state update during both training and testing phases. This innovative approach allows TTT layers to dynamically adapt and refine their representations based on input sequences, enhancing their predictive power and efficiency.
TTT-Linear and TTT-MLP are two variants of these layers. TTT-Linear employs a linear model for its hidden state, achieving comparable performance to existing RNNs like Mamba while significantly reducing processing time. On the other hand, TTT-MLP utilizes a two-layer Multilayer Perceptron (MLP), enhancing sequence prediction accuracy but requiring optimizations for memory-intensive operations.
The team’s contributions extend beyond mere model architecture. They have introduced mini-batch TTT and its dual form, which optimize hardware utilization, making TTT-Linear an essential component for scaling up language models with parameters ranging from 125 million to 1.3 billion. These advancements mark a significant step forward in the field of sequence modeling, promising more efficient and effective solutions for handling complex, data-rich contexts in various practical applications.
Conclusion:
The development of Test-Time Training (TTT) layers represents a significant advancement in sequence modeling, addressing the scalability and efficiency challenges of traditional approaches like Transformers and RNNs. By integrating self-supervised learning into the model’s architecture, TTT layers not only enhance predictive accuracy but also improve processing speed across varying model sizes. This innovation is poised to redefine the landscape of AI applications, particularly in complex, data-rich environments where efficient sequence modeling is crucial for optimal performance and scalability.