
TL;DR:
- Large Language Models (LLMs) have transformed AI chatbot landscape, excelling in tailored language functions.
- LLMs lack comprehensive visual understanding; the All-Seeing (AS) initiative bridges this gap.
- AS Project focuses on open-world panoptic visual recognition, mirroring human cognition.
- Components include the extensive All-Seeing 1B dataset and the unified All-Seeing model (ASM).
- ASM’s architecture features location-aware image tokenizer and LLM-based decoder.
- Diverse AS-1B dataset stands out with rich location annotation and detailed object concepts.
- ASM excels in discriminative tasks like image-text retrieval and generative tasks like VQA.
- Positive comparisons against baseline models emphasize ASM’s prowess.
- AS Model boasts a location-aware image tokenizer, adaptable task prompt, and LLM-based decoder.
- ASM’s training with open-ended prompts and locations leads to remarkable zero-shot performance.
- Vision and language integration culminate in an “all-seeing eye” for LLMs.
Main AI News:
Fueling the meteoric ascent of AI chatbots, Large Language Models (LLMs) have taken center stage. While showcasing astonishing proficiencies in tailoring natural language processing functions to individual users, they’ve exhibited a gap in comprehending the visual realm. This void between the domains of vision and language finds its bridge in the groundbreaking All-Seeing (AS) initiative.
At its core, the AS Project champions open-world panoptic visual recognition and understanding, with a resolute aim to craft a vision system mirroring human cognition. The term “panoptic” here encapsulates the notion of encapsulating the entirety of the observable world within a single frame.
Essential components of the AS Project include:
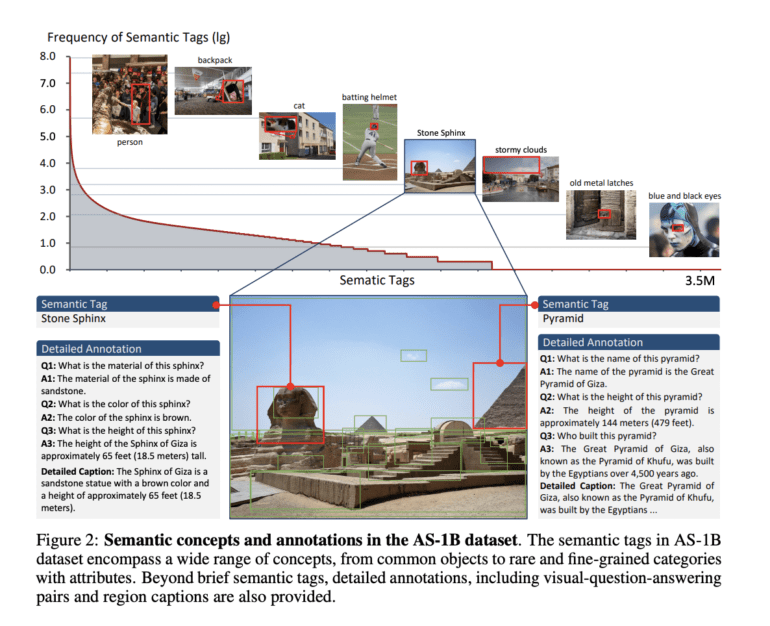
- The All-Seeing 1B (AS-1B) dataset, an expansive repository embracing 3.5 million commonplace and obscure real-world concepts. Comprising a staggering 132.2 billion tokens delineating these concepts and their attributes.
- The All-Seeing model (ASM), a unified and location-aware image-text foundational framework. Its architecture houses two pivotal constituents: a location-conscious image tokenizer and an LLM-driven decoder.
Distinguishing itself from antecedent visual recognition datasets—such as ImageNet and COCO—along with visual understanding datasets like Visual Genome and Laion-5B, the AS-1B dataset stands apart. This differentiation arises from its abundant and diverse instance-level location annotations, intertwined with meticulously detailed object concepts and elucidations.
The architectural underpinning of the AS model takes the form of a unified structure spanning varying tiers. It lends support to contrastive and generative image-text tasks, functioning both at the broader image level and granular region levels. Harnessing the prowess of pre-trained LLMs and robust vision foundation models (VFMs), this model exhibits encouraging prowess in discriminative pursuits like image-text retrieval and zero classification. Simultaneously, it shines in generative tasks encompassing visual question answering (VQA), visual reasoning, image and region captioning, and more. Intriguingly, the potential for grounding tasks, like phrase grounding and referring expression comprehension, surfaces with the aid of a class-agnostic detector.
Central to the All-Seeing Model (ASM) are three pivotal design elements:
- A location-aware image tokenizer, which extracts features from both the image and region levels. It operates based on input image data and bounding box specifications.
- An adaptable task prompt, seamlessly integrated at the outset of vision and text tokens. This directive steers the model in distinguishing between tasks of a discriminative and generative nature.
- An LLM-centric decoder, instrumental in extracting vision and text features for discriminative quests and autonomously generating response tokens for generative tasks.
Extensive data scrutiny, encompassing dimensions like quality, scalability, diversity, and experimentation, served as the backbone for analyzing and contrasting the proposed ASM against a CLIP-based baseline model. This latter model showcases the zero-shot capabilities of GPT-2 and 3. Similarly, the scrutiny extended to leading Multimodality Large Language models (VLLMs) in the realm of representative vision tasks—ranging from zero-shot region recognition to image-level and region-level captions. The revelations brought to light the robust prowess of our model in generating region-level textual content, all the while showcasing its capacity to grasp the entirety of an image. Notably, evaluations by human assessors favored captions generated by our ASM over those emanating from MiniGPT4 and LLaVA.
Powered by open-ended language prompts and inclusive of locations, the model’s training equips it with the remarkable ability to generalize across diverse vision and language tasks. This is further underscored by its outstanding zero-shot performance in realms spanning region-text retrieval, region recognition, captioning, and question-answering. According to the researchers, this attribute bequeaths LLMs with an “all-seeing eye,” thereby engineering a revolutionary intersection between vision and language.
Conclusion:
The unveiling of the All-Seeing initiative marks a pivotal milestone in the convergence of vision and language domains. This innovative paradigm not only addresses the gap between AI’s language proficiency and visual comprehension but also holds the potential to revolutionize various sectors. Businesses leveraging this advancement could tap into unparalleled capabilities for image-text tasks, leading to improved user experiences, enhanced customer engagement, and potentially unlocking new avenues for innovation across industries. The market, undoubtedly, will witness a surge in AI-powered applications that seamlessly fuse language understanding with visual context, opening doors to new business opportunities and transforming the way we interact with technology.