
TL;DR:
- Large Language Models (LLMs) have revolutionized AI with their linguistic accuracy and creative content generation.
- Augmented Language Models (ALMs) integrate reasoning skills and external tools for enhanced performance.
- ReWOO (Reasoning WithOut Observation) proposes a modular paradigm to reduce token consumption in ALMs.
- ReWOO separates reasoning from external observations, minimizing computational load and prompt redundancy.
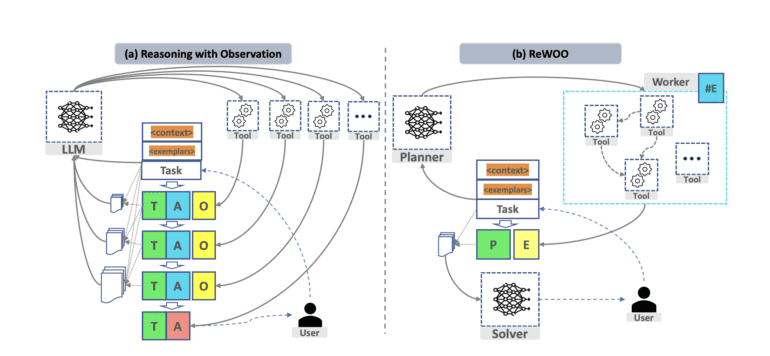
- The three modules of ReWOO (Planner, Worker, and Solver) optimize task breakdown, knowledge retrieval, and synthesis.
- The evaluation shows ReWOO achieves a 5× token efficiency gain and 4% accuracy improvement on NLP benchmarks.
- ReWOO enables instruction fine-tuning and the offloading of reasoning capabilities to smaller language models.
- This breakthrough in token consumption efficiency has significant implications for the development of effective and scalable ALMs.
Main AI News:
In the realm of Artificial Intelligence (AI), Large Language Models (LLMs) have made remarkable strides, seamlessly integrating themselves into various industries. These models possess an extraordinary aptitude for generating unique and coherent content, showcasing their linguistic prowess and consistency. With their invaluable contributions, LLMs have become indispensable across diverse domains. However, to further augment their capabilities, reasoning skills and the integration of external tools have been explored. This augmentation entails expanding the LLMs’ functionalities by incorporating additional elements and features. Augmented Language Models (ALMs) emerge as a result, pushing the boundaries of performance beyond the inherent capacities of traditional LLMs.
ALMs have played a pivotal role in the development of applications such as Auto-GPT, enabling autonomous task execution. Nevertheless, prevailing ALM methodologies predominantly rely on the prompting paradigm, entailing interleaved verbal reasoning and tool-calling. While effective, this approach imposes certain limitations. Integrating external tools requires regular execution and suspension of LLMs, resulting in delays and increased token consumption. Furthermore, LLMs generate tokens based on the preceding context, and when halted for tool response, they resume token generation by incorporating all historical tokens. This redundancy in prompts significantly inflates token consumption, posing a substantial cost burden for commercial LLM services.
To overcome these challenges, a team of researchers has recently proposed ReWOO (Reasoning WithOut Observation) – a groundbreaking modular paradigm designed to curtail token consumption. ReWOO seeks to detach the reasoning process of LLMs from external observations, consequently achieving significant reductions in token usage. By separating reasoning from external observations, ReWOO effectively minimizes the computational load associated with repetitive prompts.
At the core of an ALM lie step-wise reasoning, tool calls, and summarization – components that ReWOO dissects into three distinct modules: Planner, Worker, and Solver. The Planner dissects tasks and formulates a blueprint comprising interdependent plans, each assigned to a dedicated Worker. The Worker, in turn, retrieves relevant external knowledge from tools, providing valuable evidence. Finally, the Solver synthesizes all plans and evidence to produce the definitive answer for the initial task at hand.
To assess the performance of ReWOO, the research team conducted an exhaustive analysis across six prominent Natural Language Processing (NLP) benchmarks and a meticulously curated dataset. The findings consistently demonstrated improvements with the proposed methodology. Notably, ReWOO achieved an exceptional 5× token efficiency gain and a 4% accuracy enhancement on the HotpotQA benchmark, which involves intricate multi-step reasoning tasks. Moreover, ReWOO showcased remarkable robustness even in scenarios where external tools encountered failures.
The decoupling of parametric modules from nonparametric tool calls not only bolsters prompt efficiency but also facilitates instruction fine-tuning within ReWOO. Through fine-tuning, a 175B parameter GPT3.5 model can offload its reasoning capabilities to a smaller language model, the 7B LLaMA, resulting in a significant reduction in model parameters. This breakthrough highlights the potential for developing highly effective and scalable ALMs.
Conclusion:
The introduction of ReWOO and its modular paradigm marks a significant milestone in the field of Augmented Language Models. By effectively addressing the challenges associated with prompt redundancy and computational complexity, ReWOO sets a new standard for token consumption efficiency. This breakthrough not only enhances the performance of ALMs but also opens up new opportunities for the development of innovative and scalable solutions in the market. Businesses utilizing ALMs can expect improved efficiency and cost-effectiveness, paving the way for enhanced productivity and competitive advantage.